When I was tagged on Twitter about @ioshints (Ivan Pepelnjak (CCIE#1354 Emeritus)) latest blog post I thought somebody was telling me I should read the latest blog
Why this is so special to me is that I started my automation journey with an ipSpace.net subscription which was a very key part of my early success with Ansible and Cloud automation specifically. Ivan has also personally helped me write better code and taken a personal interest in my success.
I am so incredibly humbled and thankful for Ivan’s recognition but even more by his commitment to be honest and open with his vast knowledge.
In a lot of ways I am trying to emulate Ivan’s approach and appreciate having a virtual mentor of such quality and capability.
So you want to automate all the things in your network? Great! more and more enterprises are realizing the benefits of automating the network and are demanding more from their engineering staff. You’re also probably thinking about your career as well and how these automation skills will really come in handy to progress your career. Like I said, Network Automation skills are in high demand now.
So now what?
If you’re like me, you’ll jump straight into it and quickly realize that automating what can be considered the “life and blood” of an enterprise can be a daunting task. Rest assured though, there are things you can do today to begin your automation journey without needing to jump right into the deep end.
Standardize and Document
It would be remiss if I start off by saying that JC in his book “Automate Your Network” recommends starting your Automation Journey off by documenting and standardizing anything and everything in your network. For me, a big benefit of doing this before I dove into python and scripting was that I was able to bring my environment into a standard that makes building automation a very simple task.
I admit that it took me a bit of time and investment to bring my network into a working standard but once things were aligned it made the code I wrote that much more reusable.
Template all the Things!
If your like me, than you probably have a bunch of standard configuration commands stowed away in an Excel Document. You may not know it but one simple thing you can do as your start the automation journey is to convert those Excel Documents into clean (and reusable) code using the JINJA2 python library.
By templating your commands with JINJA2 you’ll immediately see the sky is the limit when it comes to where those commands can be run from. Whether you push those templates to another Python Library like pyATS / netmiko or simply document them for other team members, you’ll quickly see the benefits of “codifying” those CLI commands at an early stage.
Create Tooling for your Team
As a Senior Engineer, whenever I see a team member create a little tool or even a dashboard I get all jittery and excited. In my opinion, enabling your team is a selfless task that is often forgotten about. This is something I recommend you do (regardless of where you are along your automation journey) as it will get you working with other frameworks and you’ll be one step closer to a more automated and programmatic environment.
The Command Line Interface. A near 60-year old technology a majority of the world’s networking teams solely rely on for their architectures, designs, monitoring, operations, and support. Most of us, pre-DevNet, have been raised and groomed to become CLI wizards and warriors with a super-hero level of ability being the standard expectation.
But the dirty secret is the CLI sucks and we are literally using a tool that was released half-a-century-ago. Imagine if COBOL (1959) was still the only programming language in the world ? Welcome to Enterprise IT Networks – here is the CLI – good luck to you!
Well today I am going to reimagine a modern, next-generation, CLI using Python and see if I can breathe new-life into our very old friend the CLI.
This post in Meme format
Why does the CLI still suck?
It is grounded in it’s historical roots. Take for example that the original IOS had 256kB of memory with pre-Pentium chipsets! So they needed a lean and text-driven CLI to configure and operate the early routers and switches.
It is also why the modern next-generation devices come with a REST API that supports RESTCONF, NETCONF, and YANG models – they want to you get away from the CLI and move towards a modern approach.
But what about the legacy fleet? The brownfield? What if my staff are religious about the CLI ? Or fearful to learn REST, start using Postman and JSON, or even dreaded network automation like Ansible or Python ?
Culture will change over time but we need an easy, accessible, and palatable alternate to SSH’ing into devices one by one to perform CLI operations.
Take the most basic, first-to-be-run on any device, command show version.
In this video, the first I’ve ever done, I explore how, using Python, pyATS, Genie, Jinja2 Templates, and Cloud REST APIs, we can create the next-generation show version command – check it out!
I already have working automation solutions and I think I can translate / refactor / at least be inspired by previous Ansible-based solutions.
Where to start?
I’ve been down the road of learning network automation from scratch – this time let’s start with simple information gathering and transformation.
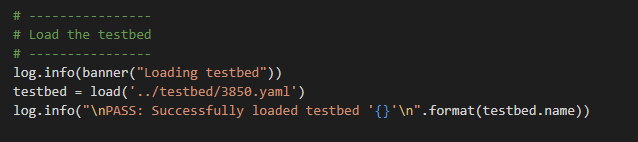
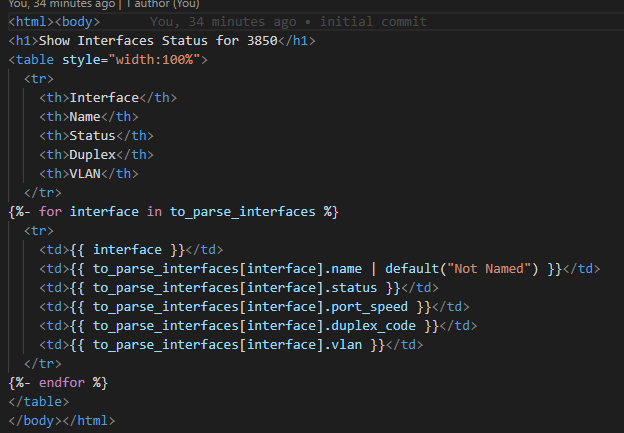
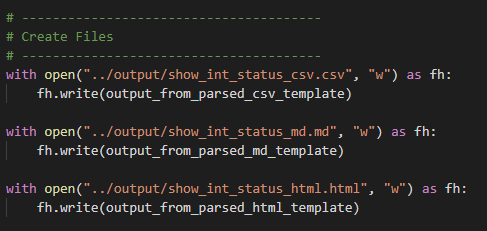
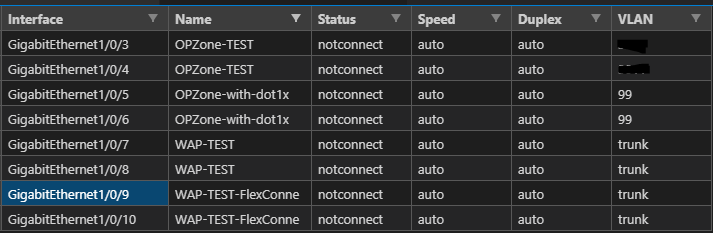
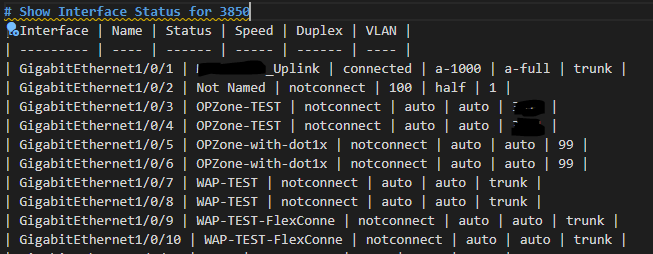
Speaking of inspiration – I am going to start with a “Just the Facts” approach and go get – show interfaces status – my favourite command – into a CSV, MD, and this time let’s spice it up and also throw in an HTML page. From Genie parsed JSON.
Only this time using pure Python – no Ansible training wheels (crutches ?)
How to attack this ?
Break it down in human language and then see if we can translate it to Python is one approach. Another is to find working examples and guides provided by the Cisco team. Using a mix of the two and some other online resources here is how I did it.
The job folder is where I will keep the pyATS job file and and code file. Output will hold the 3 output files. I plan on hopefully using Jinja2 just like in Ansible so we need a Templates folder. Finally pyATS uses the concept of testbed files to setup connectivity and authentication. These are very similar to Ansible group_vars.
I’ve included a .gitignore file to keep the .pyc files out of the Git repository.
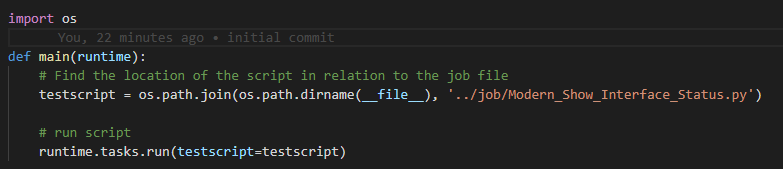
The Job file. This is a pyATS control file you can use to run the code. You can feed arguments in this way but I have not done that here.
The job file
Pretty simple so far – import the os and run the code.
First thing in the Python code is to setup the Python environment you need. Make sure to import JSON as we need to work with the Genie parsed data.
The actual code
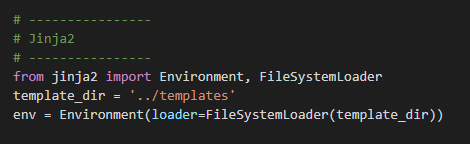
Next we will setup Jinja2 and the File loader
Jinja2 setup
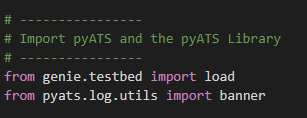
Now we import Genie and pyATS
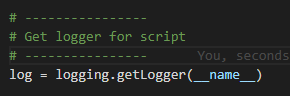
Setup a logger
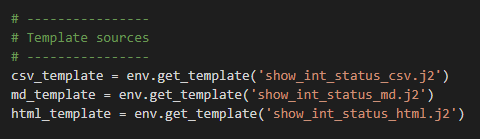
Ok so we need 3 source templates one for each file type
Turn on the logger
Let’s load up the testbed file
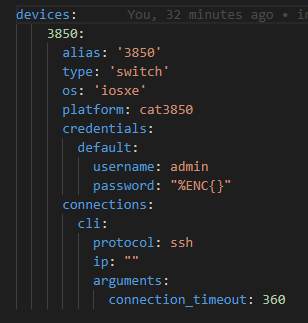
A testbed looks like this:
Note that yes! We CAN encrypt the string! %ENC{ } represents the pyATS encrypted string! Safe to store in Git repos!
Now some magic – we parse our command into a variable as JSON
Run the results thru the templates
While look like this:
CSVMarkdownHTML
Then we create the output files back in Python to finish the playbook
Which look like – ha! – we dont know if this works yet! Lets check it out!
The job in action
The command to run the job
Next it loads up the testbed
pyATS is very verbose but in a good verbose with valuable information about your job
Next the actual SSH connection sets up using Unicron (this is different than Ansible which uses paramiko)
Ok my device’s banner is displayed. My banner is left over from some CI/CD work but it’s the right banner – I’m in !
Some basic platform stuff gets dumped to the job log followed by my next job steps
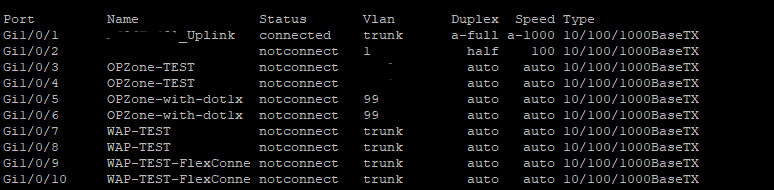
It seems to be working so farshow interfaces status
Ok it’s fired the command! Milestone in the job reached – now it should register this result as JSON in a variable next.
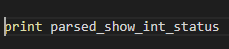
Now during my development I added the following to confirm this step was working to dump the variable to the screen:
print {{ variable name }}
Print replaces debug: msg=”{{ }}” – good!
Similar to an Ansible recap we get a pyATS Easypy Report
Easypy Report > Ansible.log
The Git Add * test
I like to build suspense so I change directories up a folder and try to stage, hopefully, the 3 new files into Git
It means, seemingly, I’ve been mastering the wrong tool. That a faster, easier, and more elegant tool is available. This is ok – I feel like Ansible was primary school and I’m moving into the next stage of my life as a developer and moving up into high school with Python.
It also means I have a lot of code to refactor into Python – also fine – a good opportunity to teach my colleagues.
I also means I will be focusing less and less on Ansible I think and more and more on Python
20 years ago I was studying to become a computer programmer analyst in college writing C++, Java, Visual Basic 6, COBOL, CICS, JCL, HTML, CSS, SQL, and JavaScript and now, two decades later, I still have the magic touch and have figured out Python.
You can expect a lot more solutions like this – in fact I am going to see if I can work in my #chatbot / #voicebot capabilities into Python.
A modern approach to the Cisco IOS-XE show interfaces status command using Python pyATS / Genie and Jinja2 templating to create business-ready CSV, Markdown, and HTML files
I am sharing this because I love both BlueCat and Cisco!
CiscoLive changed my life and where I was introduced to DevNet and automation!
Make sure you get into this giveaway !
T-minus 3 weeks to @CiscoLive 2021! Here's a handy guide to this year's festivities, & we will be covering the cost of three people's All-Access passes to the event.
Re-share to add your name to our 'sorting hat.' We'll be picking winners on Mar 19th.https://t.co/hwhQDoK0ao
Two years have flown by since self-publishing “Automate Your Network: Introducing the Modern Approach to Enterprise Network Management” and I wanted to reflect on the book, being an author, self-publishing, and how the world of infrastructure as code and network automation has changed since the book’s release.
Why did I write a book in the first place?
My primary motivation was sharing knowledge and experience. I was doing things in an entirely new way with entirely new tools and had also put these tools together in such a way they formed an actual software-development-like ecosystem. An infrastructure as code framework, if you will, that included automation capability. Two years ago, and even still to this day, I found myself baffled that this new methodology had not set the networking world on fire. Why were we still using the CLI, device-by-device, manually handcrafting our work when we could create little robots programmatically to do those manual, repetitive, tasks, or even the full configuration of every single device at scale? I was a 2xCCNP / 5xCisco Specialist but in the dozens of books, hundreds of videos, and hours and hours in the lab and in the live production network I had never been exposed to automation or infrastructure as code. You have to remember Cisco DevNet was around but they did not have any formal training, certifications; the Cisco Certification Apocalypse was in March 2020 – almost 18 months behind when I sat down and started writing my book!
My second driving force was the actual market for this type of material. I had read two books. “Network Programmability and Automation: Skills for the Next-Generation Network Engineer” – in my opinion the book on network automation.
I followed up with “Ansible for DevOps: Server and configuration management for humans”
I have absolutely nothing but 5 Star reviews of both of these books. Edelman, Lowe, and Oswalt’s work covered the broader landscape with Linux and other technology tips outside of just Ansible while Geerling’s is a lazer focused on Ansible.
But, and I mean no disrespect here, those two books basically invented the Network Automation industry, after reading the books I was still a bit lost on how to connect all these new technologies together. They are incredible technical pieces that really paved the way for me but I wanted to cover a little lower hanging fruit and try to write about the entire end-to-end workflow of automation. How do you use Git – beyond the commands – to version and source control your Ansible ? What tools – VS Code and extensions – should I use to write the automation code effectively and easily ? I did not come away with these two key pieces after reading the above books.
Third, I love writing. I was an Arts major coming out of high school; not a technology major. I went back to school to learn how to program. But I love writing. And I thought I had finally found something I could talk about and write that Great Canadian Novel – ok well not a novel but a technology book in my case.
Lastly, and I still believe this, and it’s certainly a little arrogant, but I think my way is the best way to solve technical infrastructure problems. My book was a way of trying to be an authority on this topic – because it’s not theoretical this is how I solve problems on a massive, important, complex, production enterprise network – and I believe it is easy and you can do it my way too!
On writing:
Writing the book took a lot of discipline. And the writing was actually, for me, the easy part. I have a stream-of-consciousness style approach to writing and just let it flow. Working out “universally accessible” code was a bit of a challenge. What if they are on CentOS or Ubuntu or RHEL or whatever. Are you sure this code works?
The hard part was the edits. So. Many. Edits. Now I am not sure if this is because my wife was the editor of the book or if this is just a natural thing authors and editors struggle with.
I really enjoyed writing the book. I tried to find a middle ground between easy enough for any beginner to pick up and figure out and more advanced people who may have used Ansible before.
On self-publishing
So I struck out with about 10 different publishers. I did make it into a formal discussion with 1 but it broke down because ultimately they didn’t see a market for such a book at the time – most of these publishers really didn’t know what to make about a book about network automation – so I looked around and the Amazon Kindle Direct Publishing platform turned out to be the easiest way to get my book published.
And it was! I had a final copy ready to go for the paperback. So using the Kindle Create software I also had an e-Book version as well – and anyone with Kindle Direct or Amazon Prime (I think) can read the book for free!
The KDP portal is easy to use and I’ve had no complaints about Amazon’s printing of my books or hosting it.
Pitfall: marketing!
My only comment on marketing a book if you decide to self-publish – be careful. You can quickly turn what you thought was going to be passive income into a very active drain on your resources. Between Twitter sponsored tweets to Facebook ad campaigns to LinkedIn feature posts and just basic Amazon key word auction bids – it turns out in the first three months my book was costing me money! And a lot of it!
My editor was *not* happy with this arrangement!
I shut down all spend on marketing after it cost me about $2,000. My new approach, and continued approach, was to shitpost like crazy try and establish my own “brand” if you will and setup a larger online profile for myself. This has mainly been on Twitter and LinkedIn and I wanted to focus on podcasts and other interactive new-media.
So how did it go?
I think it’s gone great. The book was won some awards. It is referenced in VMWare’s “Network Automation for Dummies” special edition. I’ve been invited to do some amazing podcasts and continue to see more and more interest in the book. I’ve become a minor, very minor, contributor to a larger automation and infrastructure as code movement. Cisco’s invited me to be a part of DevNet Create. BlueCat has invited me to round table discussion with other industry leaders. I’ve met some amazing people.
And, ultimately, I believe I’ve helped a lot of people learn how to solve problems differently. That is the general feedback I get – the book is great and changed my entire approach to solving problems. I consider this a success.
By the numbers
I do want to stress that while yes, I hoped to sell lots of copies, I did not set out to make a lot of money with my book. I really wanted to try and contribute what I had learned and my new way of working with enterprise networks, using infrastructure as code and automation, with the larger community. I want to thank each and every person who paid for the book – honestly I am so humbled – and for those interested – here are my sales figures to date:
2019: * Books: 337 * Kindle Pages Read: 13,000
2020 * Books: 117 * Kindle Pages Read: 9,300
2021: * Books: 58 * Kindle Pages Read: 2,200
Totals: * Books: 512 * Kindle Pages Read: 24,500
Impact
The book is more like a single raindrop in a storm really – but it was ahead of it’s time in some ways. Cisco DevNet totally revamped their certifications in March 2020 as mentioned but also introduced an entirely new certification track for developers and infrastructure as code and automation. The industry is rapidly catching up to the book and I see more and more Tweet’s about automation than ever. I have connected with some really brilliant people who, like me, are totally absorbed in the world of automating networks. I’ve had a few dozen people reach out directly thanking me and supporting me which is always humbling.
What’s next for the book?
It is early but I’m teaming up with Educative.io to transform the book into an online interactive digital course !
I am in talks about a follow-up book with an actual interested publisher – I’ve submitted my proposal this week !
And I’m actually selling more books than ever – interest has never been higher in network automation or infrastructure as code!
So thank you, again, for joining and supporting me on this journey!
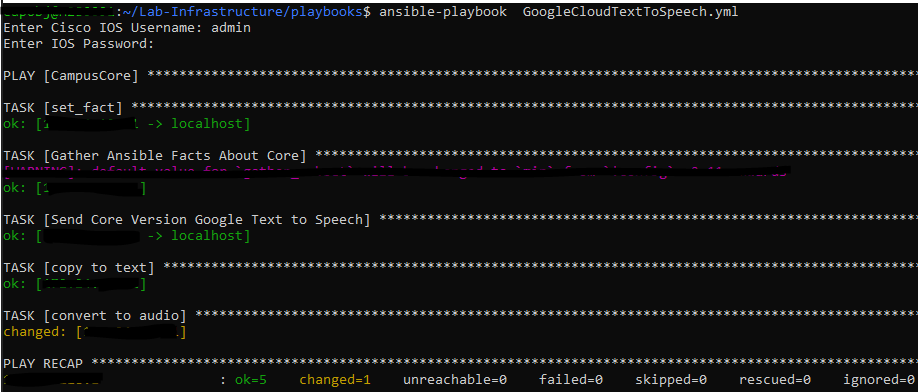
This next post may seem like science fiction. I woke up this morning and checked that my output files – MP3 files – really did exist and that I actually made my Cisco network “talk” to me!
This post is right out of Star Trek so strap yourself in!
Can we make the network talk to us?
After my success with my #chatbot my brain decided to keep going further and further until I found myself thinking about how I could actually make this real. Like most problems let’s break it down and describe it. How much of this can I already achieve and what tools do I need to get the rest of the solution in place?
I know I can get network data back in the form of JSON (text) – so in theory all I need is a text-to-speech conversion tool.
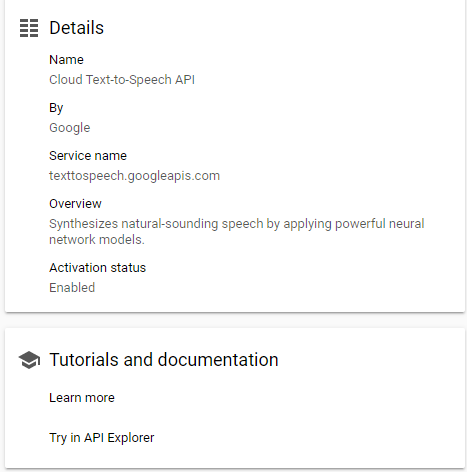
Enter: Google Cloud !
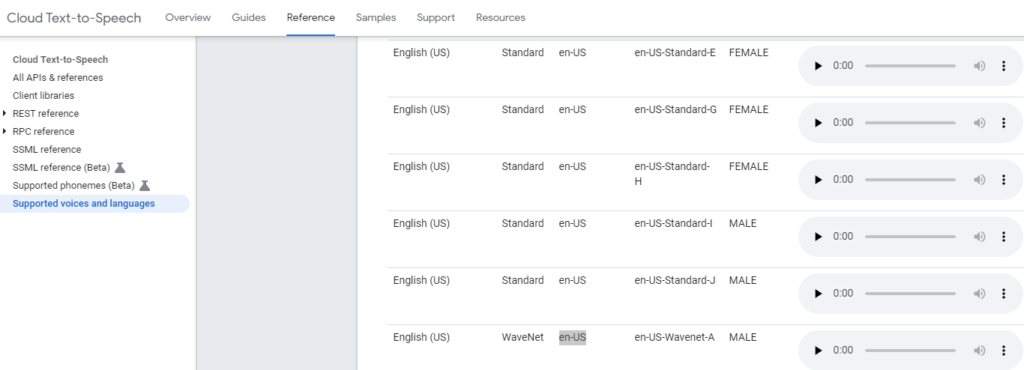
That’s right Google Cloud offers exactly what I am looking for – a RESTful API that accepts text and returns “speech” ! With over 200 languages in both male and female voices I could even get this speech in French Canadian spoken in a dozen or so different voices!
I am getting ahead of myself but that is the vision:
Go get data, automatically, from the network (easy)
Convert to JSON (also easy)
Feed the JSON text to the Google Cloud API (in theory, also easy)
The process – Google Cloud setup
There is some Google Cloud overhead involved here and this service is “free” – for up to 1 million processed text words or 3 months whichever comes first. It also looks like you get $300 in Google bucks and only 3 months of free access to Google Cloud.
Credit card warning: You need a credit card to sign up for this. They assured me, multiple times, that this does not automatically roll over to a paid subscription after the trial expires you have to actually engage and click and accept a full registration. So I hope this turns out to be free for 3 months and no actual charges show up on my credit card. But in the name of science fiction I press on.
So go setup a Google Cloud account and then your first project and eventually you will land on a page that looks like this.
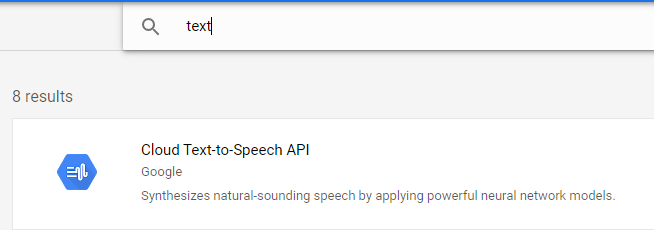
Enable an API and search for text
Enable this API and investigate the documentation and examples if you like.
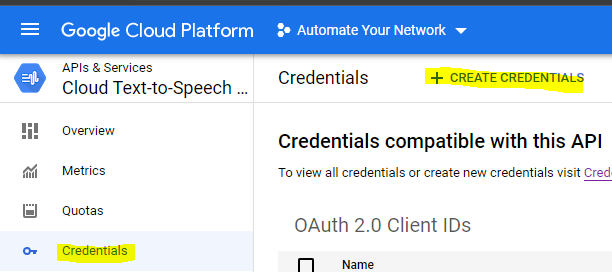
Now Google Cloud APIs are very secure to the point of confusion. So I have not fully ironed out the whole automation pipeline yet – mainly because of how complex their OAuth2 requests seem to be – but for now I have a work around I will show you to at least achieve the theoretical goal. We can circle back and mess with the authentication later. (Agile)
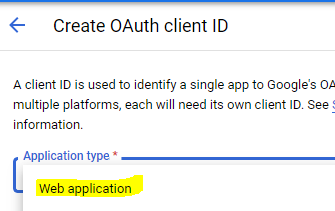
Setup OAuth2 credentials (or a Service Account if you want to use a JSON file they provide you)
Make sure it is a Web Application
This will provide you your clientID and secret.
For most OAuth2 that’s all you need – maybe I am missing the correct OAuth2 token URL to request a token but for now there is another tool you can use to get a token.
Google has an OAuth2 Developer Playground you can use to get a token while we figure out the OAuth stuff in the background
Follow the steps to select the API you want to develop (Cloud Text-To-Speech)
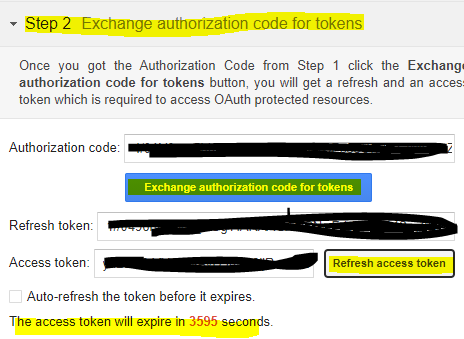
Then in the next step you can request and receive a development token
You can also refresh this token / request a new token. So copy that Access Token we will need it for Postman / Ansible in the next steps.
Moving to Postman
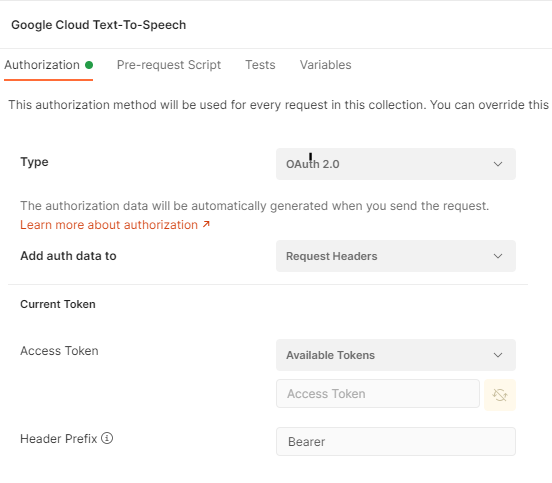
Normally under my collection I would setup my OAuth – here is the screenshot of the settings I’m just not sure of. And here is the missing link to full automation.
So far so good here
Again, this might be something trivial and I am 99% sure its because I have not setup this redirection or linked the two things but it was getting late and I wanted to get this working and not get stuck in the OAuth2 weeds
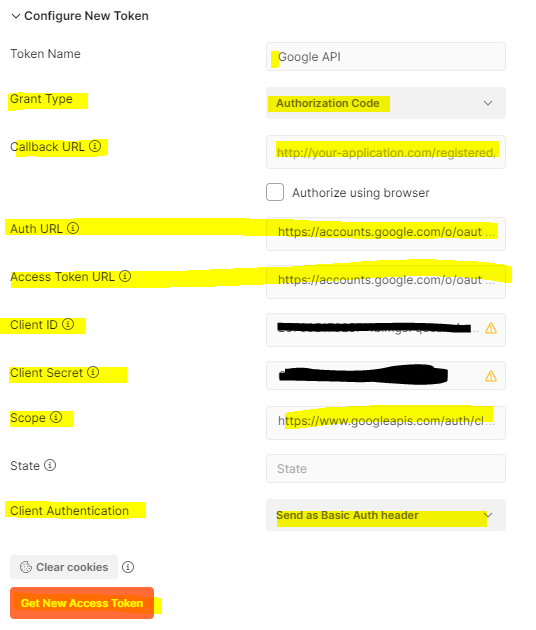
First here is what I think I have right:
Token name: Google API Auth URL: https://accounts.google.com/o/oauth2/auth Access Token URL: https://accounts.google.com/o/oauth2/token Client ID: Client Secret: Scope: https://www.googleapis.com/auth/cloud-platform
But what I’m not really sure what to do with is this Callback URL – I don’t have one of those ?
Callback URL: This is my problem I am really not sure what I need to do here ?
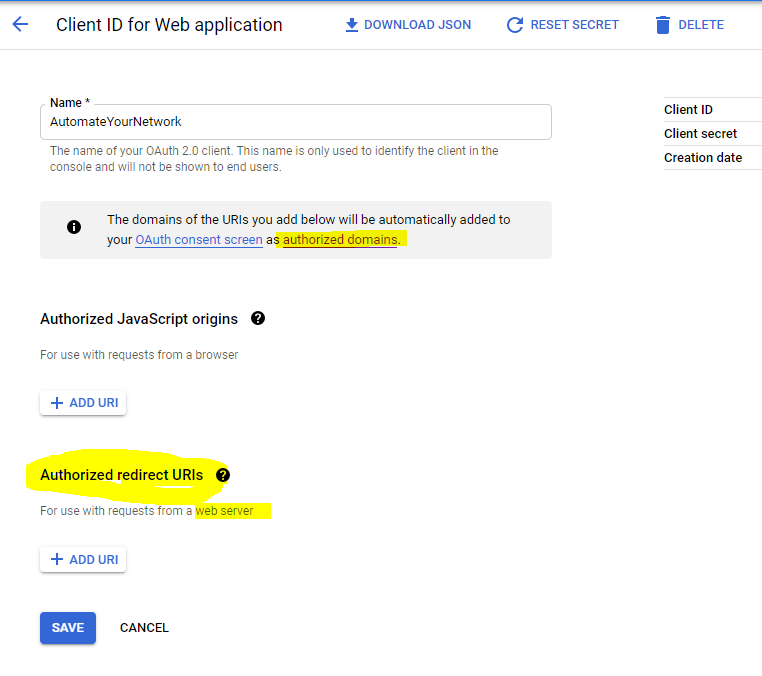
I believe I need to add it here:
But I have no cookie crumbs to follow all of the ? help icons are sort of “This is where your Authorized redirect URLs go” and thats it ?
Open call to Google Cloud Development – I just need this last little step then the rest of this can be automated
Anyway moving along – pretending we have this OAuth2 working – we can cheat for now using the OAuth2 Playground method.
So here is the Postman request:
We want a new POST request in the Google Cloud API Postman Collection. The URL is:
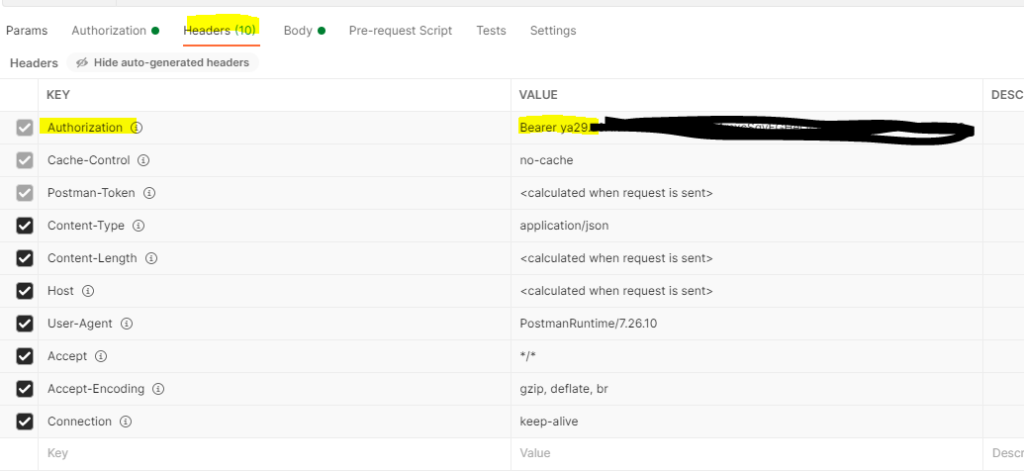
So cheat (for now) and grab the token from the OAuth2 Playground and then in your Postman Request Authorization tab – select Bearer Token and paste in your token. From my experience this will likely start with ya29 (so you know you have the right data here to paste in)
Tab over to Headers and double-check you have Bearerya29.(your key here)
As far as the body goes – again we want RAW JSON
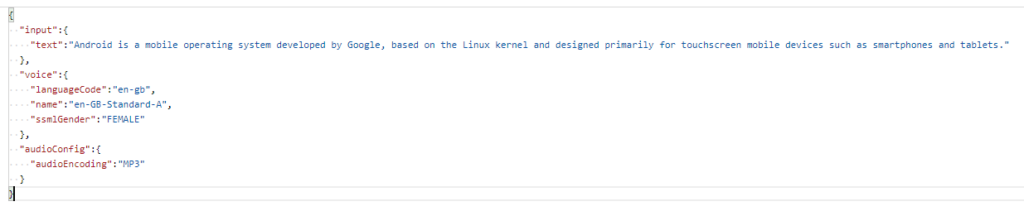
Now for the science fiction – in the body, in JSON, we setup what text we want to what speech
The canned example they provide
So we need the input (text) which is the text string we want converted.
We then select our voice – including the languageCode and name (and there are over 200 to choose from) – and the gender of the voice we want.
Lastly we want the audioConfig including the audioEncoding – and since MP3 was life for me in the mid to late 90s – let’s go with MP3 !
Hit Send and fire away!
Good start – a 200 OK with 52KB of data returned. It is returned as a JSON string:
Incredible stuff – this is the human voice pattern saying the text string – expressed as a base64-encoded audio string !
Ok – very cool stuff – but what am I supposed to do with it?
Fortunately Google Cloud has the insight we need
Hey – it’s exactly where we are at ! We have the audioContent and now we need to decode it!
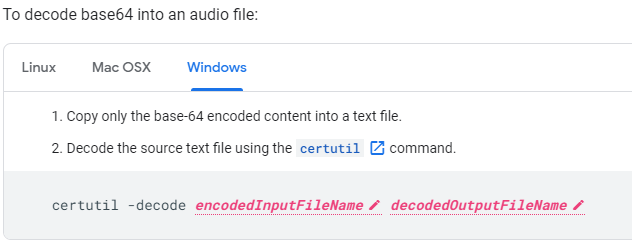
Since I am still developing in my Windows world with Postman let’s decode our canned example
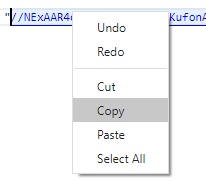
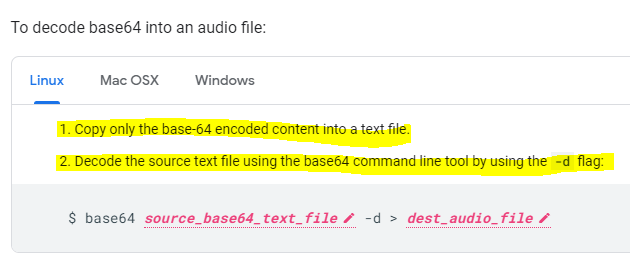
Carefully right-click copy (don’t actually click the link Postman will spawn a GET tab against the URL thinking you are trying to follow the URL along)
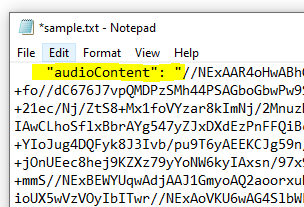
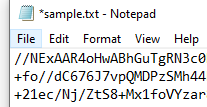
Now create a standard text (.txt) file in a C:\temp\decode folder and paste in the buffered response
I’ve highlighted the “audioContent”: “ – you have to strip this out / delete it as well as the last trailing “ at the end of the string – we just want the data starting with // and beyond to the end of the string
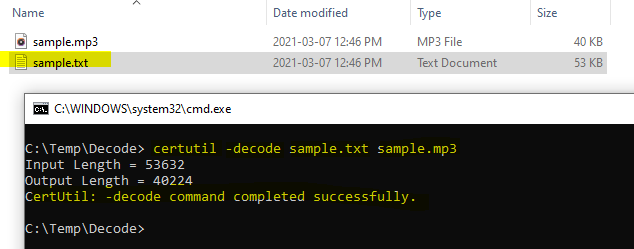
Lauch cmd and change to the C:\Temp\Decode folder and run the command
certutil -decode sample.txt sample.mp3
As you see if your text file was valid you should get a completed successfully response from the certutil utility. If not – check your string again for leading and trailing characters.
Otherwise – launch the file and have a listen!
How cool is that?!?!?
Enter: Network Automation
As I’ve said before anything I can make with with Postman I can automate with the Ansible URI module! But instead of some static text – I plan on getting network information back and having my network talk to me!
The playbook:
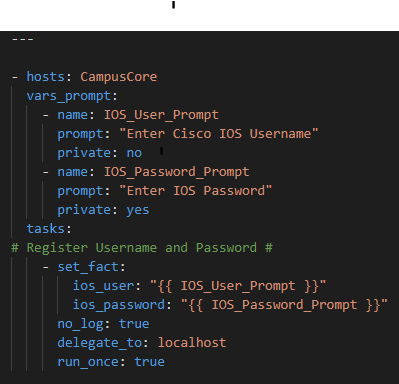
First we will prompt for credentials to authenticate
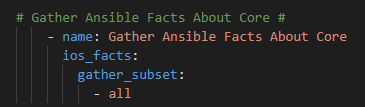
Now – let’s start with something relatively simple – can I “ask” the Core what IOS version it’s running? Sure – let’s go get the Ansible Facts, of which the IOS version is one of them, and pass the results along to the API !
For now we will hard code our token – again once I figure this out I will just have another previous Ansible URI step to go get my token with prompted ClientID / Client Secret at the start of the playbook along with the Cisco credentials. Again, temporary work around
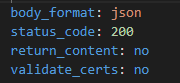
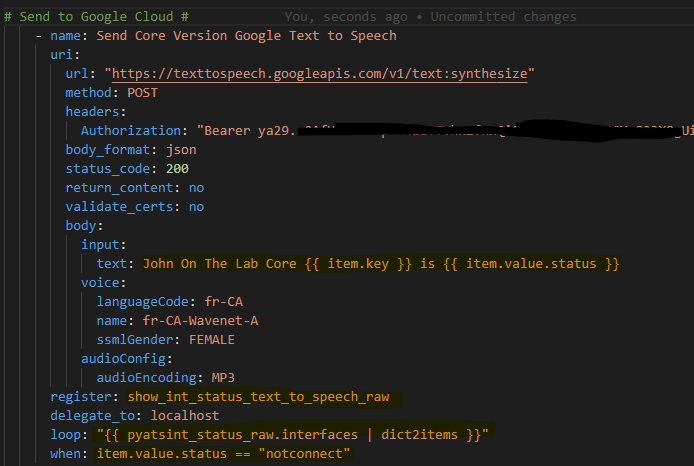
Again because I have used body_format: json I can write the body in YAML.
Ok so for our body let’s have some fun and try an English (US) WaveNet-AMale.
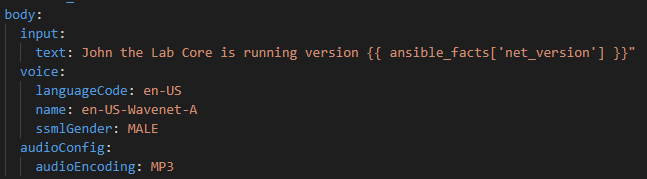
For the actual text lets mix a static string “John the Lab Core is running version” and then the magic Ansible Facts variable {{ ansible_facts[‘net_version’] }}
And see if this works
We need to register the response from the Google Cloud API and delegate the task to the localhost:
So now we need to parse and get just the base64-audio string into a text file. Just like in Postman this is contained in the json.audioContent key:
Now we have to decode the file! But this time with a Linux utility not a Windows utility
We can call the shell from Ansible easily to do this task:
Now in theory this should all work and I should get a text file and an MP3 file. Let’s run the playbook!
Lets check if Git picked a new file!
Ok ! What does it sound like!?!
Ok this is incredible!
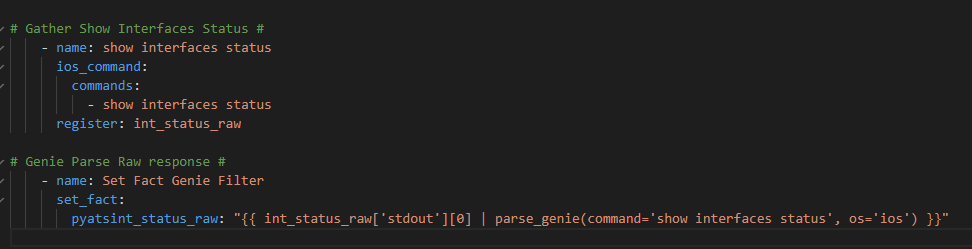
Let’s try some Genie / pyATS parsing and some different languages !
Copy and paste and rename the previous playbook and call the new file GoogleCloudTextToSpeech_Sh_Int_Status.yml
Replace the ios_facts task with the following tasks
So now for our actual API call we want to conditionally loop over each interface if is DOWN / DOWN (meaning not UP / UP and not administratively DOWN)
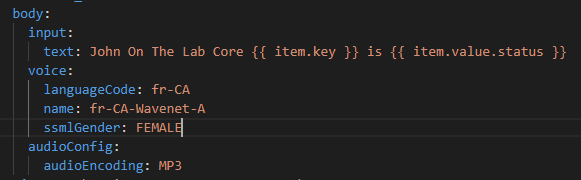
Now as an experiment – let’s use French – Canadian in a FemaleWavenet voice.
Does this also translatethe English text to French? Do do I need to write the text en francais? Lets try it!
So this whole task now looks like this:
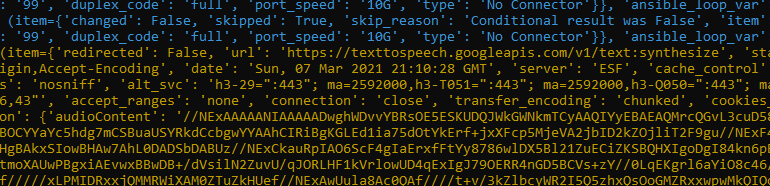
Now we need another loop and another condition to register the text from the results. We loop over the results of the first loop and when there is audioContent send that content to the text file.
Caution! RegEx ahead! Don’t be alarmed! Because of the “slashes” in an interface (Gigabit10/0/5) the file path will get messed up so let’s regex them to underscores
Then we need to decode the text files!
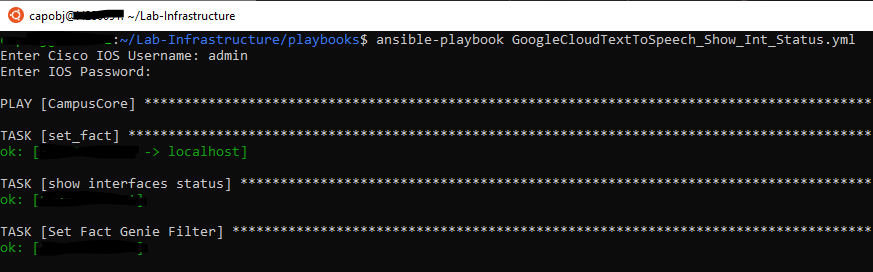
So let’s run the playbook!
So far so good – now our conditionals should kick in – we should see some items skipped in light blue text then our match hits in green
Similarly, our next step should also have skipped items and then yellow text indicating the audioContent has been captured
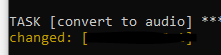
Which is finally converted to audio
What does it sound like!??! Did it automatically translate the text as well as convert it to speech?
TenGig
Gig
A little more fun with languages
I won’t post all the code but I’ve had a lot of fun with this !
How about the total number of port-channels on the Core – in Japanese ?!
Summary
In my opinion this Google Cloud API and network automation integration could change everything! Imagine if you will:
Global, multilingual teams
Elimination of technical text -> Human constructed phrasing, context, and simplicity
Audio files in your source of truth
Integrated with #chatops and #chatbots
Visually impaired or otherwise physical challenges with text-based operations
A talking network!
This was a lot of fun and I hope you found it interesting! I would love to hear your feedback!
As you may know I love to play with new toys. I especially love connecting new toys with my old toys. What you may not know is that I am also an avid World of Warcraft fan and player! In order to run what are known as “raids”, group content designed for 10 – 30 players, I use a program called Discord.
My goal was simple – could I send myself messages in Discord from my Ansible playbooks with network state data? Could I create a #chatbot in this way ?
As it turns out not only could I achieve this – it is actually pretty straight forward and simple to do!
Setup
There are not a lot of steps in the setup.
Download and install Discord
Setup an account
Create a Server
Create a Channel
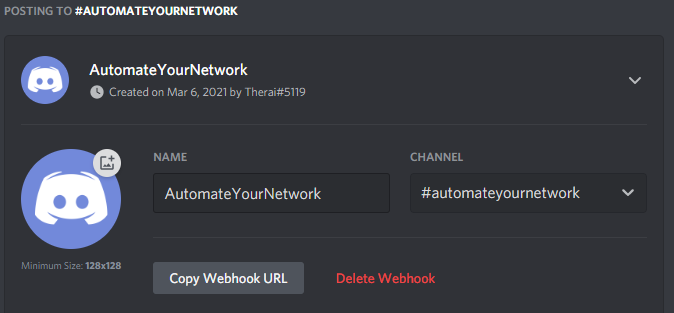
I named my channel AutomateYourNetwork and set it up as private with invite only RBAC to see the channel
Once we have a server and channel setup we need to setup the Integrations
Now setup a WebHook
Select the channel you want your chatbot to send messages to
We will need the Webhook URL
Postman Development
As with all new API development I always start in Postman to sort out the authentication, headers, and body to POST against this new Discord Webhook.
First let’s setup a new Postman Collection called Discord; add a new POST request to this collection
For the request itself make sure you change the default GET to a POST and then use the following URL:
https://discord./com/api/webhooks/< your URL copied from Discord here>
The body is flexible but to get started let’s just use a small set of values.
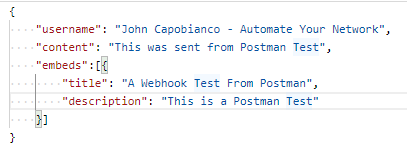
Set your body to RAW JSON
And add this body (change your username unless you want this message to look like it came from me!!)
Now if you really want to see how fast / real-time / amazingly cool this is – make sure you have your Discord logged in but minimized to your system tray
Hit SEND in Postman
Your Discord should have notified you about a new message! In my system tray the icon has also changed!
Which is no surprise because back in Postman we see we received a valid 204No Content response from the API
Lets see what Discord looks like
How cool is this?!?
Integrating with Network Automation and Infrastructure as Code
Ok this is great – but can we now integrate this into our CI/CD pipeline Ansible playbooks?
Can I send myself network state data ? Can we create a #chatops bot ?
Yes we can!
Lets start with Ansible Facts – and see if we can chat ourselves the current version of a device.
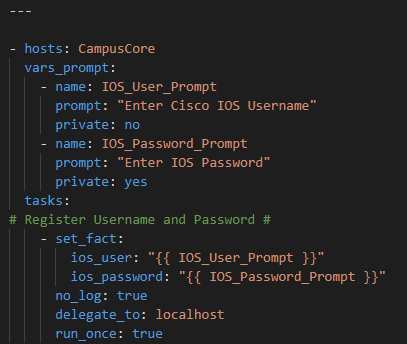
First let’s setup our credential prompts
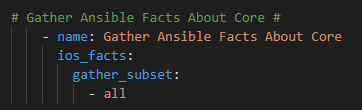
Then, let’s use ios_facts
Thats more or less all I need to do – next let’s use the URI module to send ourselves a chat!
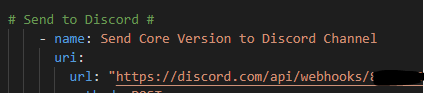
I will break down this next URI task; first setup the URL – again after /webhooks/ {{your URL here }}
This is a POST
I like to do this next step for two reasons; one to set the body of the POST to JSON (obvious) but also to allow me to use YAML syntax in Ansible to write the body of the POST (not so obvious). Without this my body would need the JSON formatting (think moustaches and brackets) which is hard enough to write on it’s own, and very hard to write inside a YAML Ansible task
Meaning I can format the body as such (in YAML):
And, like we saw in Postman, we are expecting a 204 back and no content
Make sure you are delegating to the localhost (you dont want this step to run on your Cisco switch)
Again back to the body we are accessing the Ansible magic variable ansible_facts and the key net_version
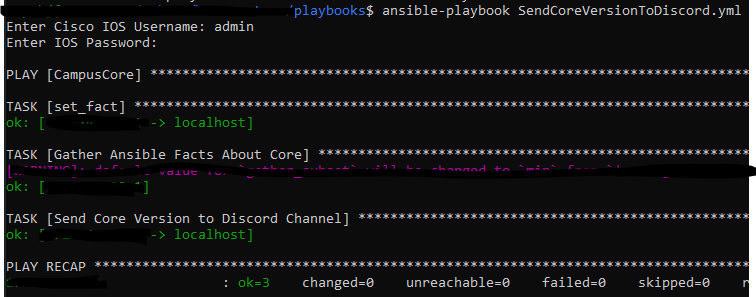
Lets run the playbook!
Discord looks happy
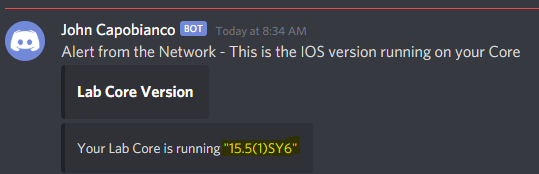
And, with the power of Internet Magic, here is our message!
This is incredible – let me integrate Cisco Genie / pyATS now and send some parsed network state data next – to show the real power here
The playbook structure is more or less the same so save the Ansible Facts version playbook and copy / rename it to Show Int Status.
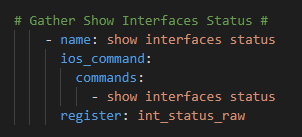
Keep the prompts; remove the ios_facts task and replace it with this task
Followed by the Genie parsing step
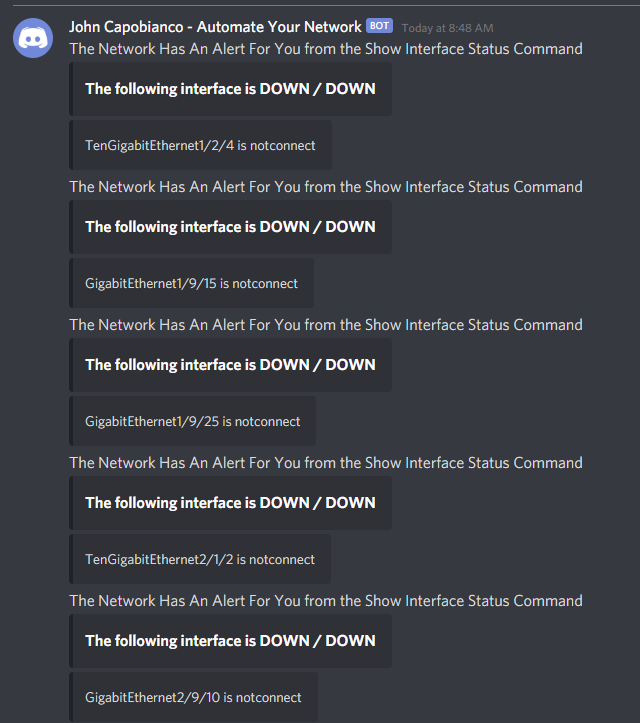
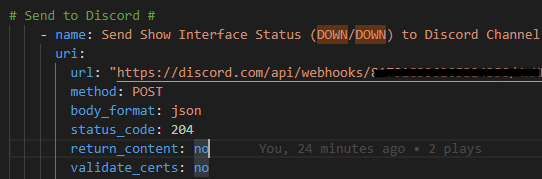
Then we need to adjust the Discord message – for my example I only want a message if, for example, an interface is configured to be UP / UP (meaning it is not administratively down) but is DOWN / DOWN (notconnected state). I don’t care about UP/UP or Administratively Down interfaces.
Again, I will break down this
Most of this is the same
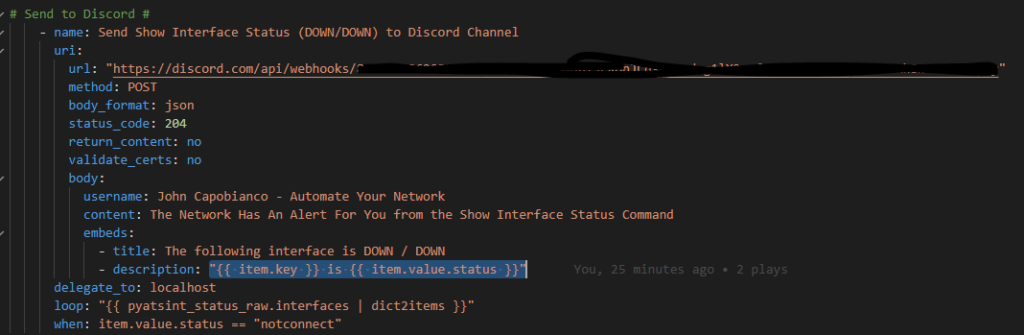
Here comes my magic with Genie. We want to loop over each interface Genie has parsed into the registered variable pyatsint_status_raw.interfaces. We need to convert this dictionary into a list of items so filter it | dict2items
Now we want a condition on this loop; only call the Discord API when the {{ item.value.status }} key (that is to say each iteration in the loops status value) when it equals “notconnect“
Now we can reference the item.value for the per-interface name and the item.value.status for the notconnect status when it hits a match in the body of the message we are sending to Discord.
The task as a whole looks like this:
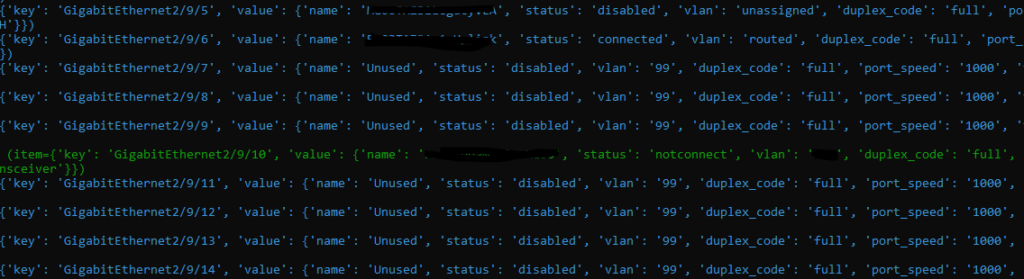
So we run this new playbook which sort of looks like this. Remember we have a condition so the light blue text indicates non-matches / skipped interfaces (because they are connected or admin down); green indicates a hit.
Drumroll please
And now in Discord I have this wonderful, pager-like, real-time “alert”
Now go build one!
Here is the GitHub repository – go try to build one for your network!
Ansible playbooks that chat with Discord using Ansible, Genie/pyATS, and the Discord webhooks that send network state information as a Discord message!
The security of my network keeps me up at night. Honestly it does. We live in a world where enterprise networks are defending themselves against state-sponsored attacks. But what do attackers look for? Typically, open, well-known, vulnerabilities.
Well, at least to the hackers, attackers, and even script-kiddies, these vulnerabilities are well-known. Those playing defense are often a step or two behind just identifying vulnerabilities – and often times at the mercy of patch-management cycles or operational constraints that prevent them of addressing (patching) these waiting-to-be-exploited holes in the network.
What can we do about it?
The first thing we can do is to stay informed ! But this alone can be a difficult task with a fleet of various platforms running various software versions at scale. How many flavours of Cisco IOS, IOS-XE, and NXOS platforms make up your enterprise? What version are they running? And most importantly is that version compromised?
The old way might be to get e-mail notifications (hurray more e-mail!), maybe RSS-feeds, or go device-by-device, webpage-by-webpage, looking up the version and if it’s open to attack or not.
Do you see why, now, how an enterprise becomes vulnerable? It’s tedious and time-intensive work. And the moment you are done – the data is stale – what, are you going to wake up every day and review threats like this manually? Assign staff to do this? Just accept the risk and do they best you can trying to patch quarterly ?
Enter: Automation
These types of tasks beg to be solved with automation !
So how can you do it?
Let’s just lay out a high level, human language, defined use-case / wish list.
Can we, at scale, go get the current IOS / IOS-XE / NXOS software version from a device?
Then can we send that particular version somewhere to find out if it has been compromised ?
Can we generate a report from the data above?
Technically the above is all feasible; easy even!
Yes, we can use Ansible and the Cisco Genie Parser to capture the current software version
As with any new REST API I like to start with Postman and then transform working requests into Ansible playbooks.
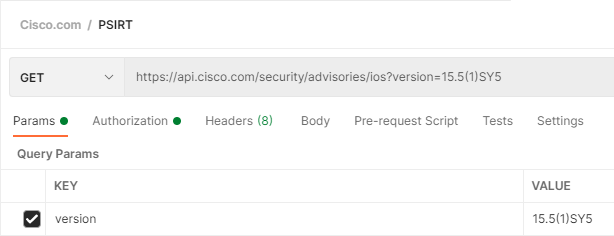
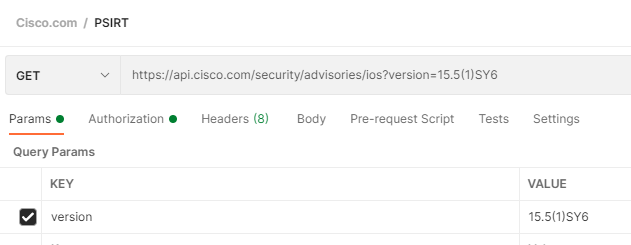
First, under a new or existing Cisco.com Collection, add a new request called IOS Vulnerabilities
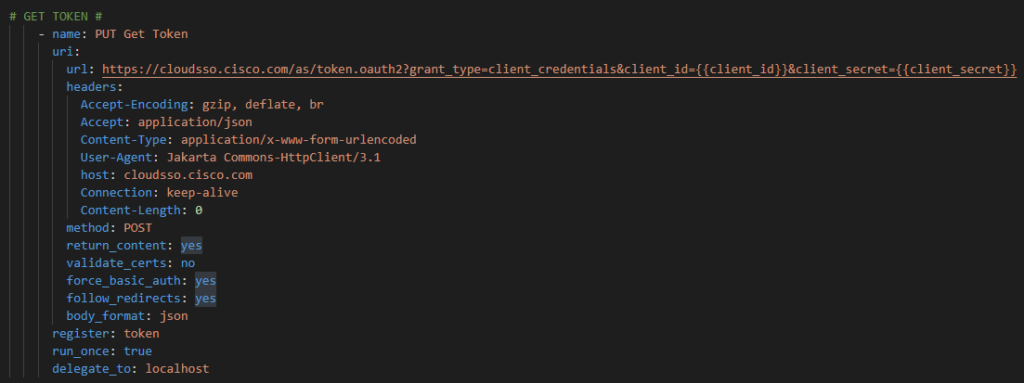
Cisco.com uses OAuth2 authentication mechanism where you first must authenticate against one REST API (https://cloudsso.cisco.com/as/token.oauth2) which provides back authorization Bearer token used to then authenticate and authorize against subsequent Cisco.com APIs
Your Client ID and Secret are found in the API portal after you register the OpenVuln API
Let’s hard code a version and see what flaws it has
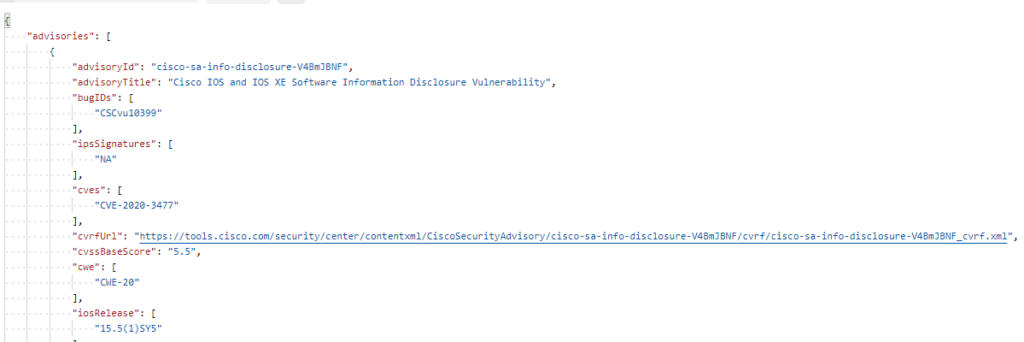
Ok so it has at least 1 open vulnerability!
Does it tell us what version fixes it?
Ok let’s check that version quickly while we are still in Postman
This version has no disclosed vulnerabilities!
One interesting thing of note – and our automation is going to need to handle it – is that if there are no flaws found we get a 404 back from the API not a 200 like our flawed response!
The Playbook
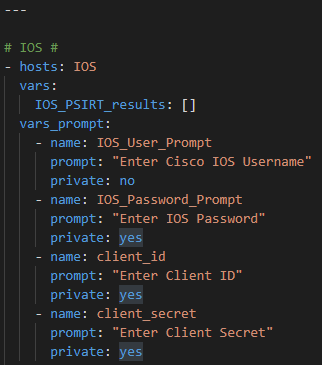
For the sake of the example I am using prompted inputs / response but these variables could easily be hardcoded and Ansible Vaulted.
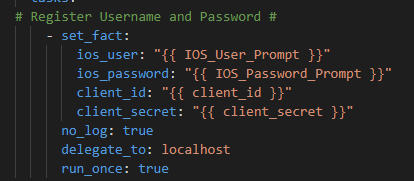
So first prompt for your Cisco hosts username and password and your Cisco.com ClientID and Client Secret
Register the response
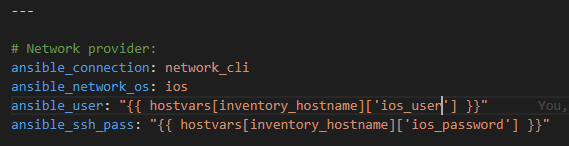
Then in the IOS.yml group_vars I have my Ansible network connections
I’ve put all IOS-platforms in this group in the hosts file to target them
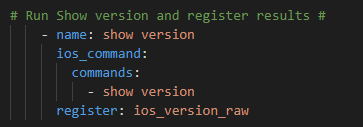
Next step run the show version ios_command and register the reponse
Genie parse and register the JSON
Now we need, just like in Postman, to go get the OAuth2 token but instead of Postman we need to use the Ansible URI module
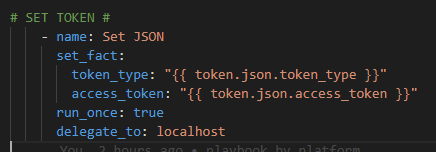
Then we have to parse this response and setup our Bearer and Token components from the response JSON.
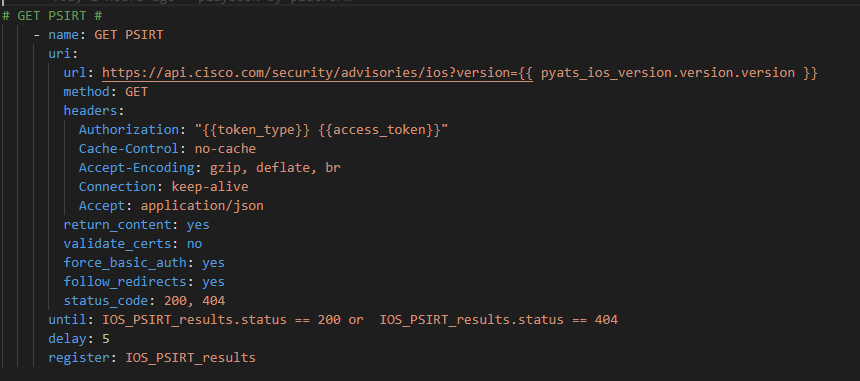
Now that we have our token we can authenticate against the IOS open Vulernability API
There are a couple of things going on here:
We are passing the Genie parsed .version.version key to the API for each IOS host in our list
We are using the {{ token_type }} and {{ access_token }} to Authorize
We have to expect two different status codes; 200 (flaws found on a host) and 404 (no flaws for the host software version)
I’ve added until and delay to slow down / throttle the API requests as not to get a 406 back because I’ve overwhelmed the 10 requests per second upper limit
We register the JSON response from the API
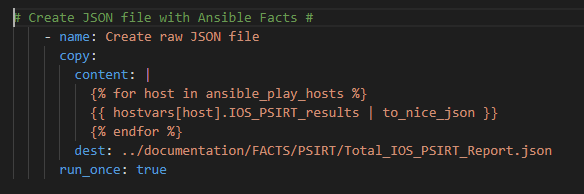
As always I like to create a “nice” (easy to read) version of the output in a .json file
Note we need to Loop over each host in our playbook (using the Ansible magic variable ansible_play_hosts) so the JSON file has a data set for each host in the playbook.
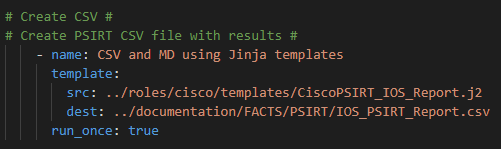
Lastly we run the template module to pass the data into Jinja2 where we will create a business-ready CSV file
Which looks like this broken apart:
Like building the JSON file first we need to loop over the hosts in the playbook.
Then we check if the errorCode is defined. You could also look at the 404 status code here. Either way if you get the error it means there are no vulnerabilities.
So add a row of data with the hostname, “N/A” for most fields, and the json.errorMessage from the API (or just hardcode “No flaws” or whatever you want here; “compliant”)
Now if the errorCode is not defined it means there are open flaws and we will get back other data we need to loop into.
I am choosing to do a nested set of two loops – one for each advisory in the list of advisories per software version. Then inside that loop another loop, adding a row of data to the spreadsheet, for each BugID found as well (which is also a list).
There are a few more lists like CVEs for example – you can either loop of these as well (but we start to get into too much repetition / rows of data) – or just use regex_replace(‘,’,’ ‘) to remove all commas inside a field. The result is the list spaced out inside the cell sorted alphabetically but if you do not do this it will throw off the number of cells in your CSV
The results
What can you do with “just” a CSV file?
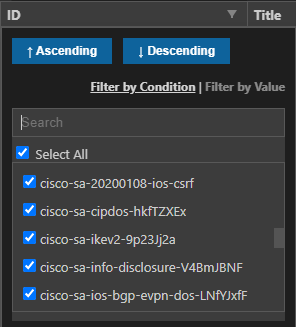
With Excel or simply VS Code with the Excel Preview extension – some pretty awesome things!
I can, for example, pick the ID field and filter down a particular flaw in the list – which would then provide me all the hosts affected by that bug
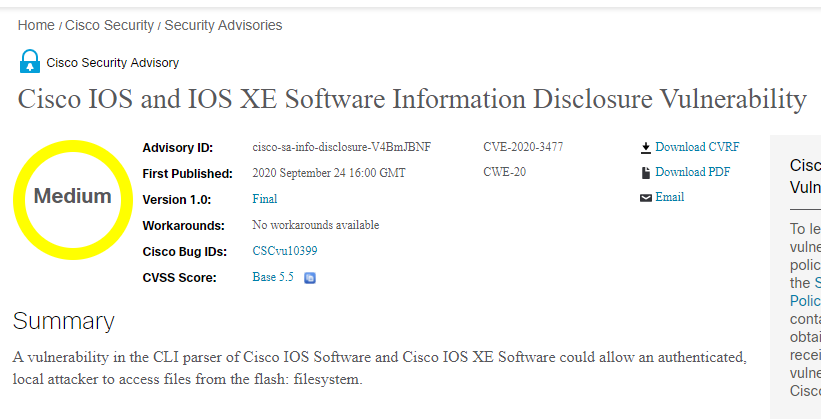
Or pick a host out of the list and see what flaws it has, if any. Or any of the columns we have setup in the Jinja2
Included in the report is also the SEVERITY and BASE SCORE for quick decision making or the Detailed Publication URL to get a detailed report for closer analysis.