
When I describe Ansible to people I tend to use many positive adjectives. Amazing, incredible, easy, revolutionary, powerful, and a few others. One adjective I never use, however, is fast. I would not describe Ansible as a high performance tool. Compared to manually doing the things I’ve come to automate with Ansible there is still no doubt I am saving hours if not days of effort. But now that I’m using Ansible for almost everything and at scale it would be great if I could get better performance out of the tool.
Over the years I’ve learned to run the ansible-playbook command then – and chant it like the late night informercial – “Set it and forget it!”
Its the one, sometimes painful, drawback I can find with Ansible. There has yet to be an infrastructure problem I have not been able to solve with Ansible – provided I am comfortable with waiting. “How long does this take?” change managers or operations will ask. “A while.” Is usually as optimistic as I can be.
(Note: It is a bit ironic sometimes the same crowd with complaints about how long a playbook takes to run are usually the same people who were comfortable with pre-automation manual-at-the-cli-of-every-device execution times into the days or weeks. Now anything more than a 10 minute playbook run seems like a long time. Go figure)
TL:DR
– Ansible is an amazing automation tool
– Ansible is not known for its performance
– Three modifications tried to make it go faster
– LibSSH
– Forks
– Pipelines
– No real improvements found with any of the above
Moving to LibSSH
The driving factor for me to bring my Ansible ecosystem into the shop and put it up on the lift to get underneath and into the mechanics of the configurations is this latest official blog post from Ansible.
“Not only is the new LibSSH connection plugin enabling FIPS readiness, but it was also designed to be more performant than the existing Paramiko SSH subsystem.”
This particular section of the blog post is what drives my exploration today. And yes FIPS readiness is important to me – the hook for me here is “designed to be more performant” – and yes the link they provide is great but I want to take the Pepsi Challenge myself.
Playbooks tested
I will be using the following playbooks with 2 different scale sets.
Cisco IOS Facts – Against my Lab distribution layer (4, Cisco 4500s) and my access layer (about 20 – 25 devices of various Catalyst flavours (2960, 3560, 3750, 3850, 9300)).
Cisco NXOS Facts – Same idea but against NXOS. 2 Nexus 7000 and 2 Nexus 5000.
The above playbooks use the Ansible facts modules. Let’s do some Genie Parsing of a show command as well.
IOS Genie show ip interface status
Methodology
In Linux you can use the time keyword command and prepend any command. Linux then provides three different timer – the real time, the user time, and the system time – results showing how long the command took to execute.
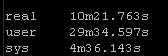
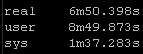
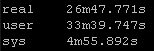
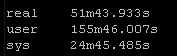
Result Set #1 – Defaults
With no changes to default Ansible here are the results. I will be standardizing on the sys results because of the input and other factors the real times and users times may have deviations:





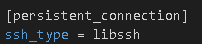
Install LibSSH and modify Ansible
First step is to pip install the Ansible library we need:

Then we to update our persistent connections:
Refresh your Git repo and re-run the playbooks.
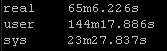
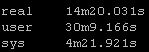
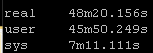
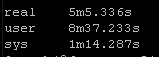
Result Set #2 – LibSSH
Forks
Ansible can be set to fork which allows multiple independent remote connections simultaneously.
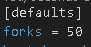
Forks are intelligent and will only fork for the maximum number of remote targets. So I will set my forks in ansible.cfg to 50.
Now I don’t think this will help playbooks with under 5 targets because I believe Ansible defaults to 5 forks but maybe this will improve the Access Layer Facts which targets around 25 hosts. So lets just test against that one playbook.
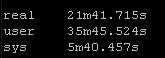
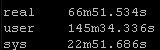
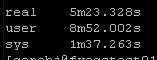
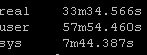
Results Set #3 – Forks
Pipelining
Enabling pipelining reduces the number of SSH operations required to execute a module on the remote server, by executing many ansible modules without actual file transfer. According to the documentation this can result in a very significant performance improvement when enabled.
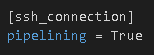
Add pipelining=true to the SSH connection section in ansible.cfg:
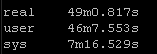
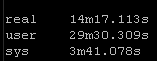
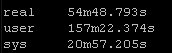
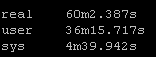
Result Set #4 – Pipelining
Summary
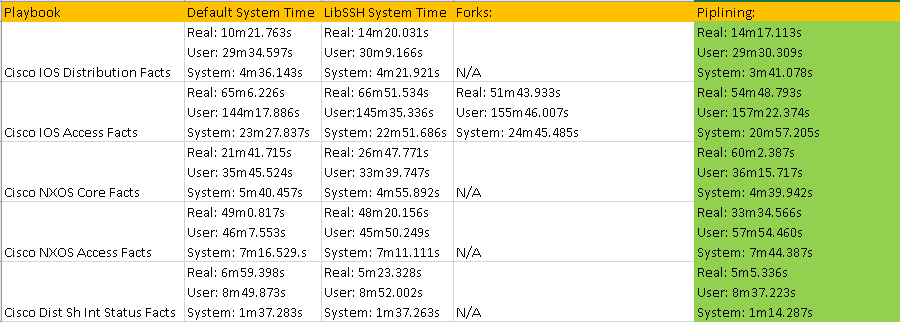
I didn’t have much success making Ansible go any faster either with the new LibSSH library, with forking, or with pipelining. I absolutely love ansible but the above times are from my small scale lab – imagine these run times in production at 5-10x the scale.
Have you found a way to make Ansible go faster that I’ve overlooked? Drop my a line!
Sean also jumped in to mention the driver for LibSSH was FIPS not performance and there are some performance improvements coming soon! Great!
probably not for the ios and nxos devices, but for e. g. linux servers mitogen does a really good job speeding ansible up, maybe it works for e. g. cumulus linux?
https://github.com/dw/mitogen
Did Mitogen make it into upstream Ansible yet ? It dropped support in 2.9 I think last I checked but thanks for the tip!