When Ivan Pepelnjak has advice for you – take it!
I wrote a post about untangling dynamic nested loops in Ansible.
In another recent post about trying to improve Ansible performance I didn’t get very far – but this could be the silver bullet I’ve been looking for to both optimize and make my Fact / Genie parsing playbooks more elegant code but also to bring my run times down so I can bring this from the lab to production.
Jinja2 Templates
One of the reasons why I perked up at Ivan’s generous suggestion is because I am a big fan and heavy user of Jinja2 templates already to generate intended configurations (Cisco IOS, NXOS configurations; JSON files for API POST) and documentation (intended configs in CSV, markdown, and HTML) – but I had just never thought of implementing them to create my documentation from received data!
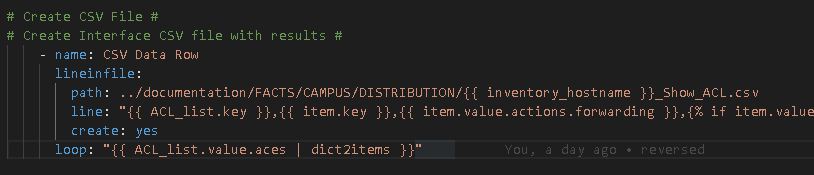
My old way involved taking the structured JSON and using lineinfile or copy to create my output files. This was slow. Very slow.
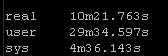
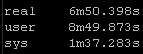
Copy method:

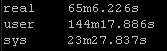
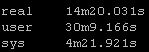
Line In File method:
How to refactor this?
So I already have everything I need content wise – a header row and the data rows – I just need to move this into Jinja2 format. As it turns out there are some added benefits beyond just performance that I will highlight.
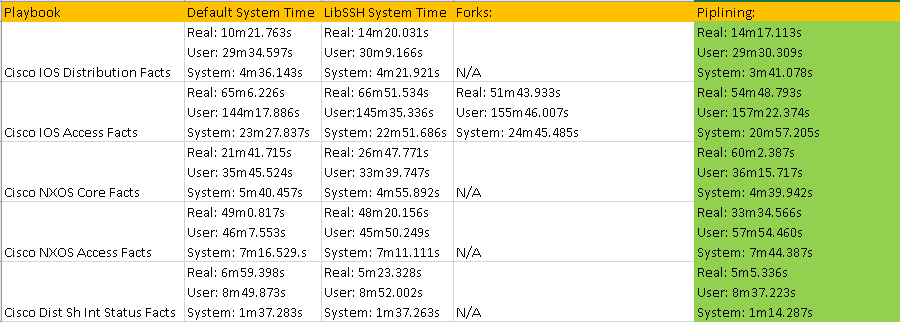
My quick use case was my CiscoNXOSFacts.yml playbook against 2 7Ks just gathering facts (nxos_facts) and transforming the structured JSON into business documentation.
– Create Nice JSON file from facts – Ansible | to_nice_json filter
– Create Nice YAML file from facts – Ansible | to_nice_yaml filter
– Create CSV file from facts
– Create markdown file from facts
– Generate HTML from markdown
So the first refactoring is the actual task from using copy or lineinfile to using template. Template needs a source (a new Jinja2 template file we will create in our next step).

Template also needs a destination. Here is where we can use the programmatic capabilities of Jinaj2 to simplify, optimize, and massively improve performance by setting up a simple loop and create both files. Wait files plural? Yes. My old way involved creating 2 separate files in 2 separate tasks. Now that I am using Jinja I can use variables – one item being “csv” and the other item being “md” – and pass them to the template for processing.

So create a Jinja2 template file called CiscoNXOSFactsTemplate.j2 to create your CSV and Markdown files.
Before I show the template I want to highlight another massive improvement to using Jinja2 – Jinaj2 is able to iterate naturally over dictionaries while my previous method had to pass the structured JSON through the | dict2items Ansible filter (against adding processing time). This simplifies the code quite a bit.
In the template we will test if the loop is on csv or md and create either a csv or md formatted output file.

Else if item is md create the markdown file format

One last and very important comment and benefit of Jinja2 is that I do not need to use Regular Expressions “as much” to clean up the JSON. | dict2items leaves a lot of garbage JSON characters behind which I had to previously use processor intensive RegEx tasks to clean up. Now Jinja2 does this cleanup and conversion from RAW to Nice JSON for me!
Results
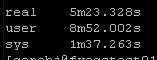
I have only tested 1 playbook but I am very excited about this new refactored code !
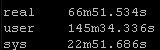
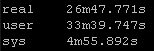
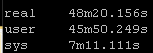
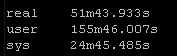
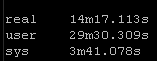
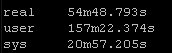
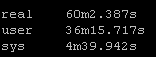
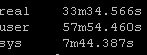
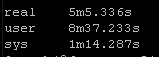
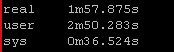
Again this playbook “only” touches 2 physical devices but I have playbooks that potentially could be gathering facts and generating artifacts for hundreds of devices. But the results are pretty clear particularly the system time
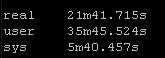
Old way:
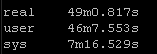
New way:
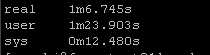
So roughly half the “real” time but look at the system time – from 36 seconds down a third to 12 seconds! WOW!
Thanks again!
A big thanks to Ivan for taking the time to comment and point me in a better direction. You may not know this but when I started my automation journey one of my resources along with several books, Cisco DevNet, trial and error, was my IPSpace.net subscription. If you are looking for a very affordable and very comprehensive library of networking and automation knowledge this is a good place to start.