Two years have flown by since self-publishing “Automate Your Network: Introducing the Modern Approach to Enterprise Network Management” and I wanted to reflect on the book, being an author, self-publishing, and how the world of infrastructure as code and network automation has changed since the book’s release.
Why did I write a book in the first place?
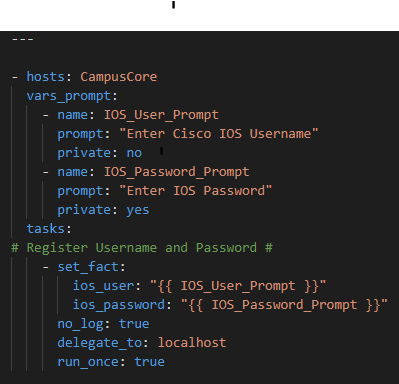
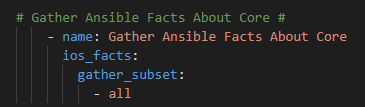
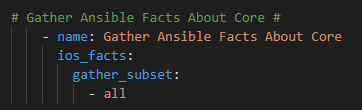
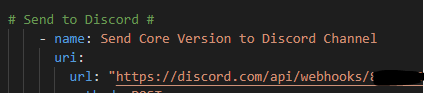
My primary motivation was sharing knowledge and experience. I was doing things in an entirely new way with entirely new tools and had also put these tools together in such a way they formed an actual software-development-like ecosystem. An infrastructure as code framework, if you will, that included automation capability. Two years ago, and even still to this day, I found myself baffled that this new methodology had not set the networking world on fire. Why were we still using the CLI, device-by-device, manually handcrafting our work when we could create little robots programmatically to do those manual, repetitive, tasks, or even the full configuration of every single device at scale? I was a 2xCCNP / 5xCisco Specialist but in the dozens of books, hundreds of videos, and hours and hours in the lab and in the live production network I had never been exposed to automation or infrastructure as code. You have to remember Cisco DevNet was around but they did not have any formal training, certifications; the Cisco Certification Apocalypse was in March 2020 – almost 18 months behind when I sat down and started writing my book!
My second driving force was the actual market for this type of material. I had read two books. “Network Programmability and Automation: Skills for the Next-Generation Network Engineer” – in my opinion the book on network automation.
I followed up with “Ansible for DevOps: Server and configuration management for humans”
I have absolutely nothing but 5 Star reviews of both of these books. Edelman, Lowe, and Oswalt’s work covered the broader landscape with Linux and other technology tips outside of just Ansible while Geerling’s is a lazer focused on Ansible.
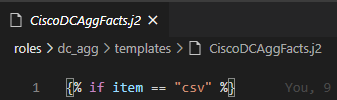
But, and I mean no disrespect here, those two books basically invented the Network Automation industry, after reading the books I was still a bit lost on how to connect all these new technologies together. They are incredible technical pieces that really paved the way for me but I wanted to cover a little lower hanging fruit and try to write about the entire end-to-end workflow of automation. How do you use Git – beyond the commands – to version and source control your Ansible ? What tools – VS Code and extensions – should I use to write the automation code effectively and easily ? I did not come away with these two key pieces after reading the above books.
Third, I love writing. I was an Arts major coming out of high school; not a technology major. I went back to school to learn how to program. But I love writing. And I thought I had finally found something I could talk about and write that Great Canadian Novel – ok well not a novel but a technology book in my case.
Lastly, and I still believe this, and it’s certainly a little arrogant, but I think my way is the best way to solve technical infrastructure problems. My book was a way of trying to be an authority on this topic – because it’s not theoretical this is how I solve problems on a massive, important, complex, production enterprise network – and I believe it is easy and you can do it my way too!
On writing:
Writing the book took a lot of discipline. And the writing was actually, for me, the easy part. I have a stream-of-consciousness style approach to writing and just let it flow. Working out “universally accessible” code was a bit of a challenge. What if they are on CentOS or Ubuntu or RHEL or whatever. Are you sure this code works?
The hard part was the edits. So. Many. Edits. Now I am not sure if this is because my wife was the editor of the book or if this is just a natural thing authors and editors struggle with.
I really enjoyed writing the book. I tried to find a middle ground between easy enough for any beginner to pick up and figure out and more advanced people who may have used Ansible before.
On self-publishing
So I struck out with about 10 different publishers. I did make it into a formal discussion with 1 but it broke down because ultimately they didn’t see a market for such a book at the time – most of these publishers really didn’t know what to make about a book about network automation – so I looked around and the Amazon Kindle Direct Publishing platform turned out to be the easiest way to get my book published.
And it was! I had a final copy ready to go for the paperback. So using the Kindle Create software I also had an e-Book version as well – and anyone with Kindle Direct or Amazon Prime (I think) can read the book for free!
The KDP portal is easy to use and I’ve had no complaints about Amazon’s printing of my books or hosting it.
Pitfall: marketing!
My only comment on marketing a book if you decide to self-publish – be careful. You can quickly turn what you thought was going to be passive income into a very active drain on your resources. Between Twitter sponsored tweets to Facebook ad campaigns to LinkedIn feature posts and just basic Amazon key word auction bids – it turns out in the first three months my book was costing me money! And a lot of it!
My editor was *not* happy with this arrangement!
I shut down all spend on marketing after it cost me about $2,000. My new approach, and continued approach, was to shitpost like crazy try and establish my own “brand” if you will and setup a larger online profile for myself. This has mainly been on Twitter and LinkedIn and I wanted to focus on podcasts and other interactive new-media.
So how did it go?
I think it’s gone great. The book was won some awards. It is referenced in VMWare’s “Network Automation for Dummies” special edition. I’ve been invited to do some amazing podcasts and continue to see more and more interest in the book. I’ve become a minor, very minor, contributor to a larger automation and infrastructure as code movement. Cisco’s invited me to be a part of DevNet Create. BlueCat has invited me to round table discussion with other industry leaders. I’ve met some amazing people.
And, ultimately, I believe I’ve helped a lot of people learn how to solve problems differently. That is the general feedback I get – the book is great and changed my entire approach to solving problems. I consider this a success.
By the numbers
I do want to stress that while yes, I hoped to sell lots of copies, I did not set out to make a lot of money with my book. I really wanted to try and contribute what I had learned and my new way of working with enterprise networks, using infrastructure as code and automation, with the larger community. I want to thank each and every person who paid for the book – honestly I am so humbled – and for those interested – here are my sales figures to date:
2019:
* Books: 337
* Kindle Pages Read: 13,000
2020
* Books: 117
* Kindle Pages Read: 9,300
2021:
* Books: 58
* Kindle Pages Read: 2,200
Totals:
* Books: 512
* Kindle Pages Read: 24,500
Impact
The book is more like a single raindrop in a storm really – but it was ahead of it’s time in some ways. Cisco DevNet totally revamped their certifications in March 2020 as mentioned but also introduced an entirely new certification track for developers and infrastructure as code and automation. The industry is rapidly catching up to the book and I see more and more Tweet’s about automation than ever. I have connected with some really brilliant people who, like me, are totally absorbed in the world of automating networks. I’ve had a few dozen people reach out directly thanking me and supporting me which is always humbling.
What’s next for the book?
It is early but I’m teaming up with Educative.io to transform the book into an online interactive digital course !
I am in talks about a follow-up book with an actual interested publisher – I’ve submitted my proposal this week !
And I’m actually selling more books than ever – interest has never been higher in network automation or infrastructure as code!
So thank you, again, for joining and supporting me on this journey!