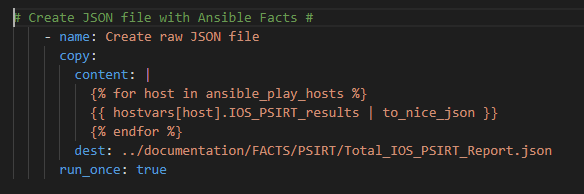
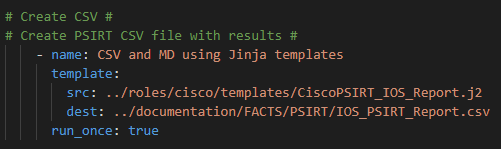
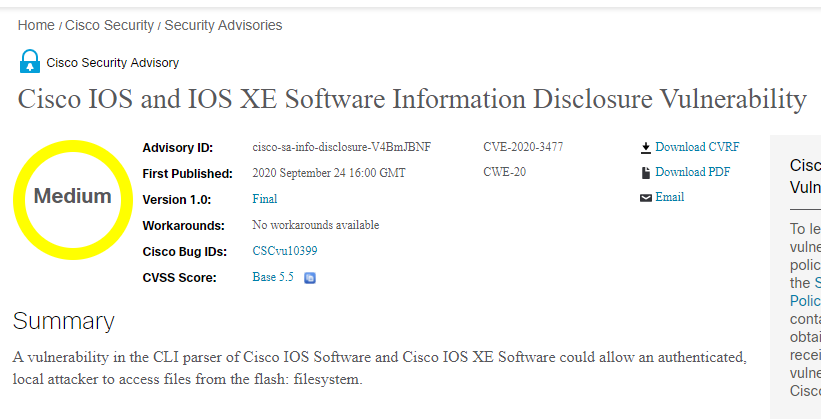
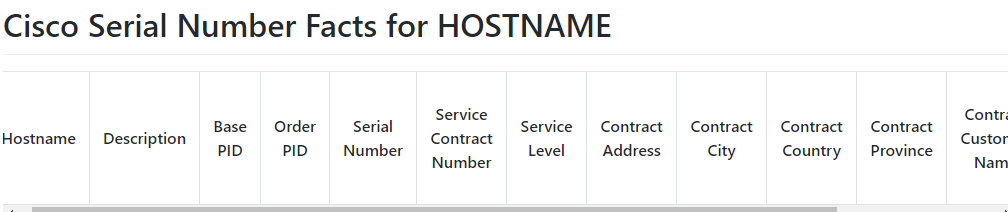
This next post may seem like science fiction. I woke up this morning and checked that my output files – MP3 files – really did exist and that I actually made my Cisco network “talk” to me!
This post is right out of Star Trek so strap yourself in!
Can we make the network talk to us?
After my success with my #chatbot my brain decided to keep going further and further until I found myself thinking about how I could actually make this real. Like most problems let’s break it down and describe it. How much of this can I already achieve and what tools do I need to get the rest of the solution in place?
I know I can get network data back in the form of JSON (text) – so in theory all I need is a text-to-speech conversion tool.
Enter: Google Cloud !
That’s right Google Cloud offers exactly what I am looking for – a RESTful API that accepts text and returns “speech” ! With over 200 languages in both male and female voices I could even get this speech in French Canadian spoken in a dozen or so different voices!
I am getting ahead of myself but that is the vision:
- Go get data, automatically, from the network (easy)
- Convert to JSON (also easy)
- Feed the JSON text to the Google Cloud API (in theory, also easy)
The process – Google Cloud setup
There is some Google Cloud overhead involved here and this service is “free” – for up to 1 million processed text words or 3 months whichever comes first. It also looks like you get $300 in Google bucks and only 3 months of free access to Google Cloud.
Credit card warning: You need a credit card to sign up for this. They assured me, multiple times, that this does not automatically roll over to a paid subscription after the trial expires you have to actually engage and click and accept a full registration. So I hope this turns out to be free for 3 months and no actual charges show up on my credit card. But in the name of science fiction I press on.
So go setup a Google Cloud account and then your first project and eventually you will land on a page that looks like this.
Enable an API and search for text
Enable this API and investigate the documentation and examples if you like.
Now Google Cloud APIs are very secure to the point of confusion. So I have not fully ironed out the whole automation pipeline yet – mainly because of how complex their OAuth2 requests seem to be – but for now I have a work around I will show you to at least achieve the theoretical goal. We can circle back and mess with the authentication later. (Agile)
Setup OAuth2 credentials (or a Service Account if you want to use a JSON file they provide you)
Make sure it is a Web Application
This will provide you your clientID and secret.

For most OAuth2 that’s all you need – maybe I am missing the correct OAuth2 token URL to request a token but for now there is another tool you can use to get a token.
Google has an OAuth2 Developer Playground you can use to get a token while we figure out the OAuth stuff in the background
Follow the steps to select the API you want to develop (Cloud Text-To-Speech)

Then in the next step you can request and receive a development token
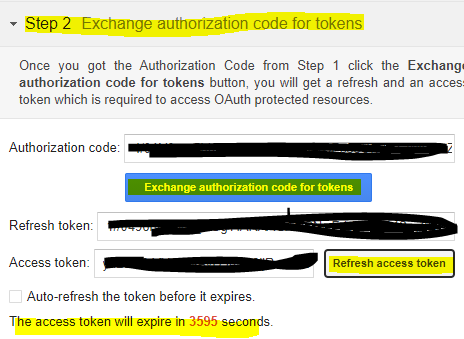
You can also refresh this token / request a new token. So copy that Access Token we will need it for Postman / Ansible in the next steps.
Moving to Postman
Normally under my collection I would setup my OAuth – here is the screenshot of the settings I’m just not sure of. And here is the missing link to full automation.
So far so good here
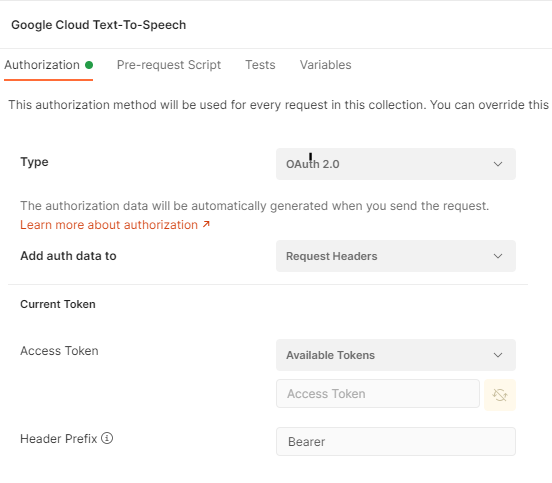
Again, this might be something trivial and I am 99% sure its because I have not setup this redirection or linked the two things but it was getting late and I wanted to get this working and not get stuck in the OAuth2 weeds
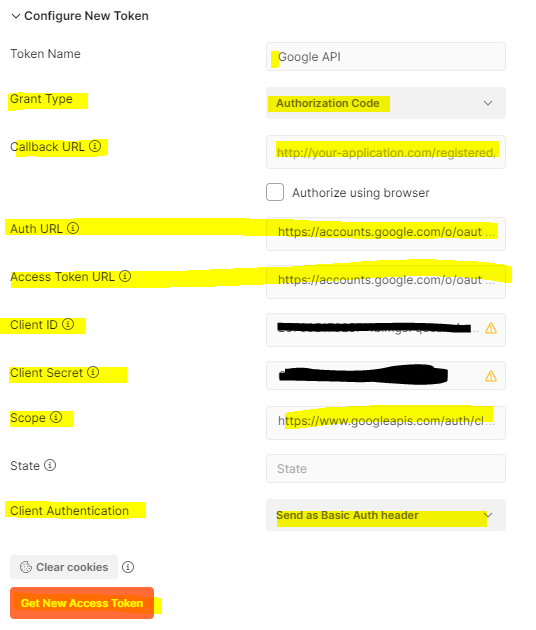
First here is what I think I have right:
Token name: Google API
Auth URL: https://accounts.google.com/o/oauth2/auth
Access Token URL: https://accounts.google.com/o/oauth2/token
Client ID:
Client Secret:
Scope: https://www.googleapis.com/auth/cloud-platform
But what I’m not really sure what to do with is this Callback URL – I don’t have one of those ?
Callback URL: This is my problem I am really not sure what I need to do here ?
I believe I need to add it here:
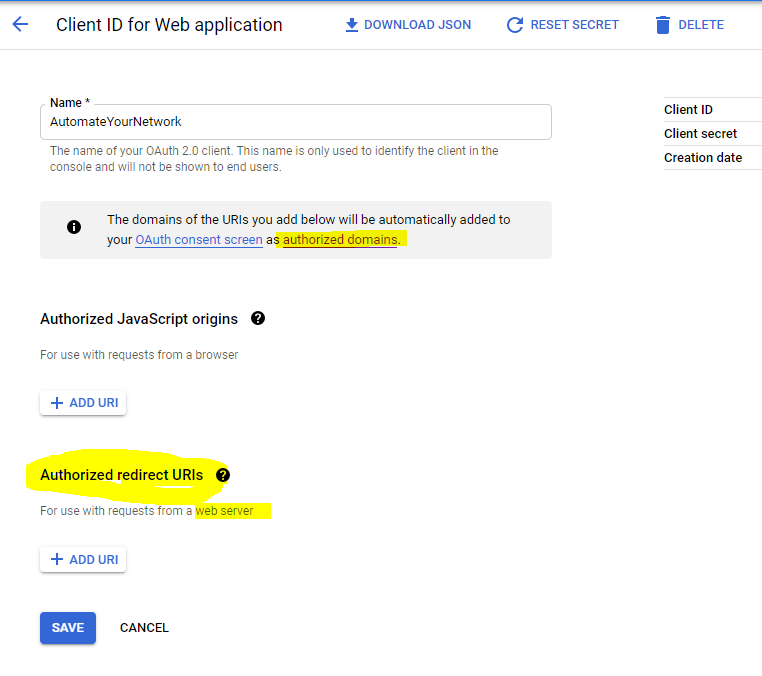
But I have no cookie crumbs to follow all of the ? help icons are sort of “This is where your Authorized redirect URLs go” and thats it ?
Open call to Google Cloud Development – I just need this last little step then the rest of this can be automated
Anyway moving along – pretending we have this OAuth2 working – we can cheat for now using the OAuth2 Playground method.
So here is the Postman request:
We want a new POST request in the Google Cloud API Postman Collection. The URL is:
https://texttospeech.googleapis.com/v1/text:sythesize

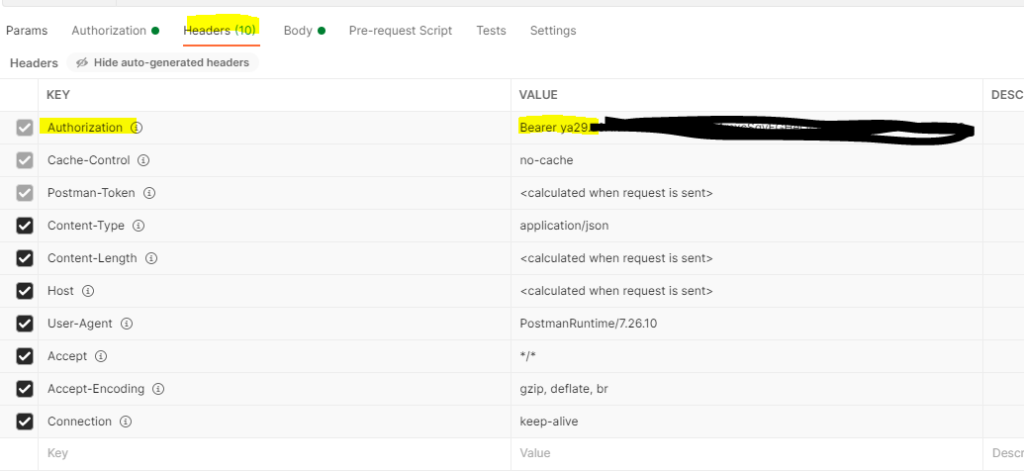
So cheat (for now) and grab the token from the OAuth2 Playground and then in your Postman Request Authorization tab – select Bearer Token and paste in your token. From my experience this will likely start with ya29 (so you know you have the right data here to paste in)

Tab over to Headers and double-check you have Bearer ya29.(your key here)
As far as the body goes – again we want RAW JSON

Now for the science fiction – in the body, in JSON, we setup what text we want to what speech
The canned example they provide
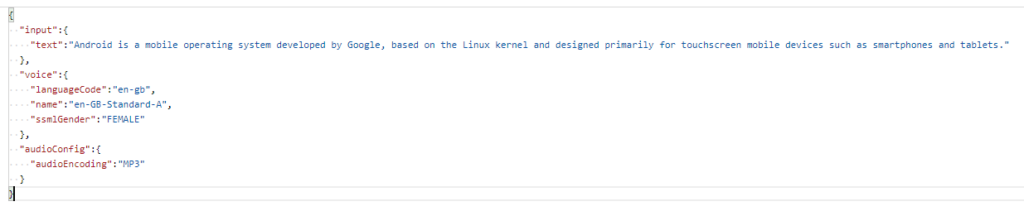
So we need the input (text) which is the text string we want converted.
We then select our voice – including the languageCode and name (and there are over 200 to choose from) – and the gender of the voice we want.
Lastly we want the audioConfig including the audioEncoding – and since MP3 was life for me in the mid to late 90s – let’s go with MP3 !
Hit Send and fire away!

Good start – a 200 OK with 52KB of data returned. It is returned as a JSON string:

Incredible stuff – this is the human voice pattern saying the text string – expressed as a base64-encoded audio string !
Curious, I found the Base64 Guru !


Ok – very cool stuff – but what am I supposed to do with it?
Fortunately Google Cloud has the insight we need



Hey – it’s exactly where we are at ! We have the audioContent and now we need to decode it!
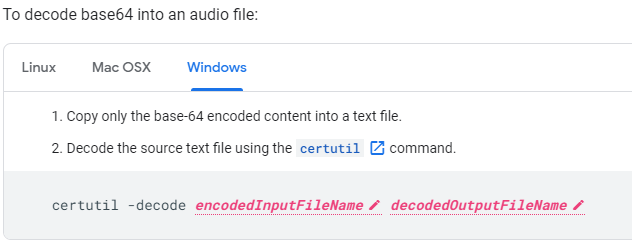
Since I am still developing in my Windows world with Postman let’s decode our canned example
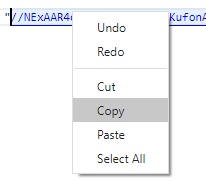
Carefully right-click copy (don’t actually click the link Postman will spawn a GET tab against the URL thinking you are trying to follow the URL along)
Now create a standard text (.txt) file in a C:\temp\decode folder and paste in the buffered response
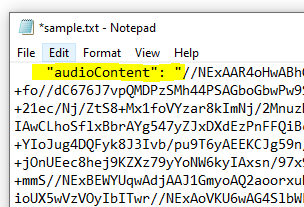
I’ve highlighted the “audioContent”: “ – you have to strip this out / delete it as well as the last trailing “ at the end of the string – we just want the data starting with // and beyond to the end of the string
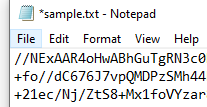
Lauch cmd and change to the C:\Temp\Decode folder and run the command
certutil -decode sample.txt sample.mp3
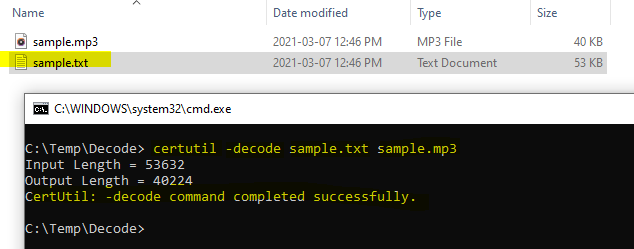
As you see if your text file was valid you should get a completed successfully response from the certutil utility. If not – check your string again for leading and trailing characters.
Otherwise – launch the file and have a listen!
How cool is that?!?!?
Enter: Network Automation
As I’ve said before anything I can make with with Postman I can automate with the Ansible URI module! But instead of some static text – I plan on getting network information back and having my network talk to me!
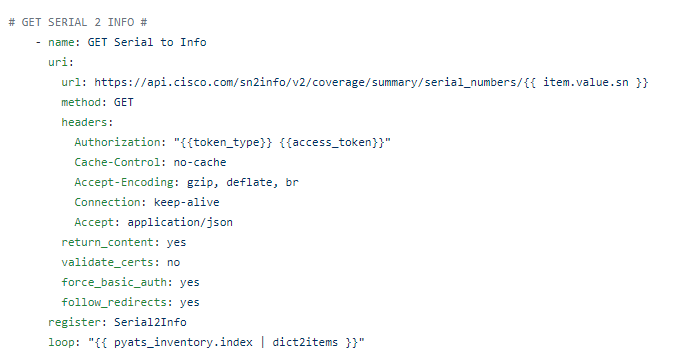
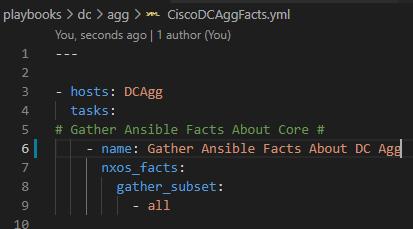
The playbook:
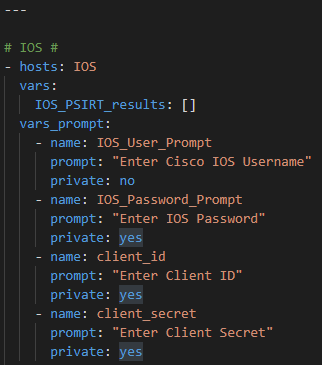
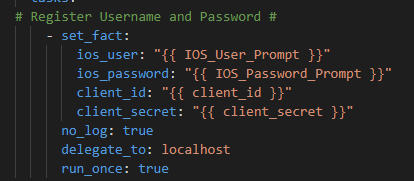
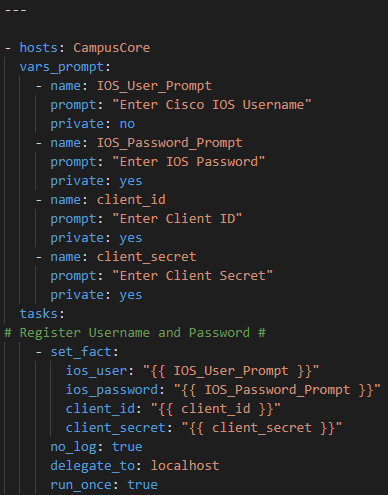
First we will prompt for credentials to authenticate
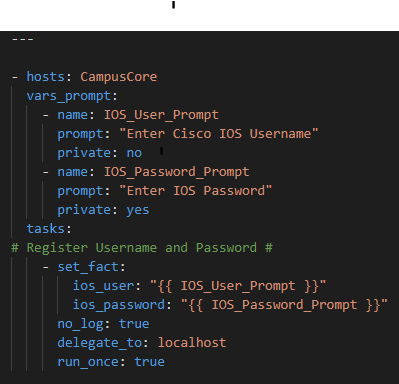
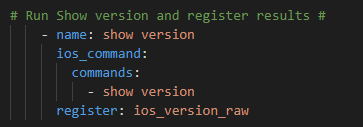
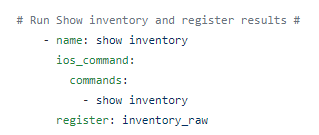
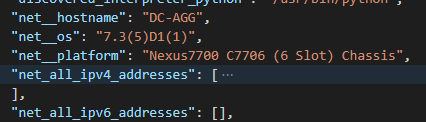
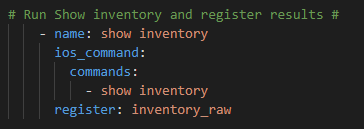
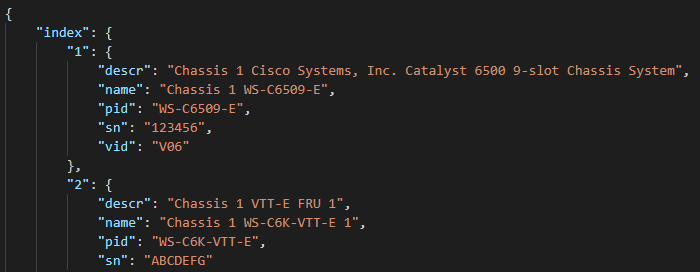
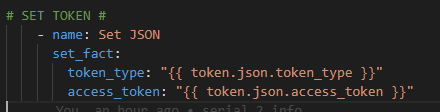
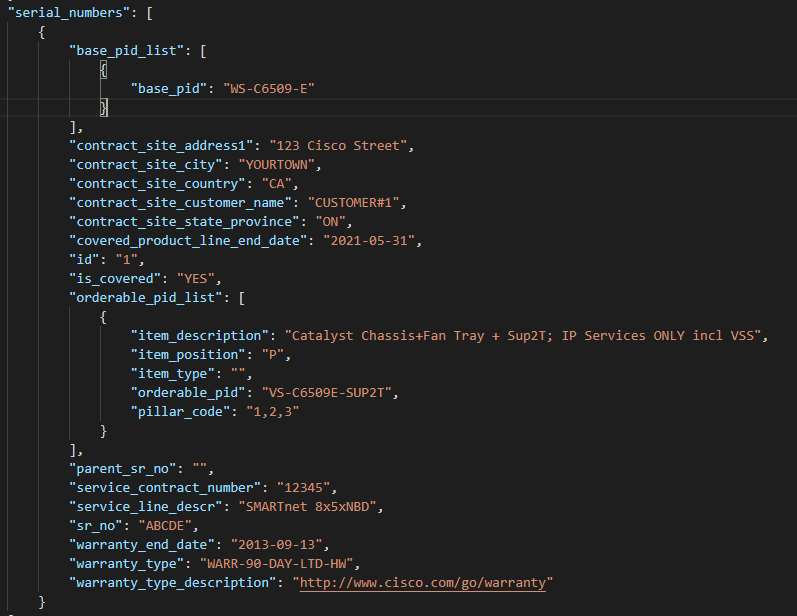
Now – let’s start with something relatively simple – can I “ask” the Core what IOS version it’s running? Sure – let’s go get the Ansible Facts, of which the IOS version is one of them, and pass the results along to the API !
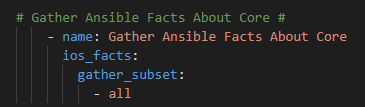

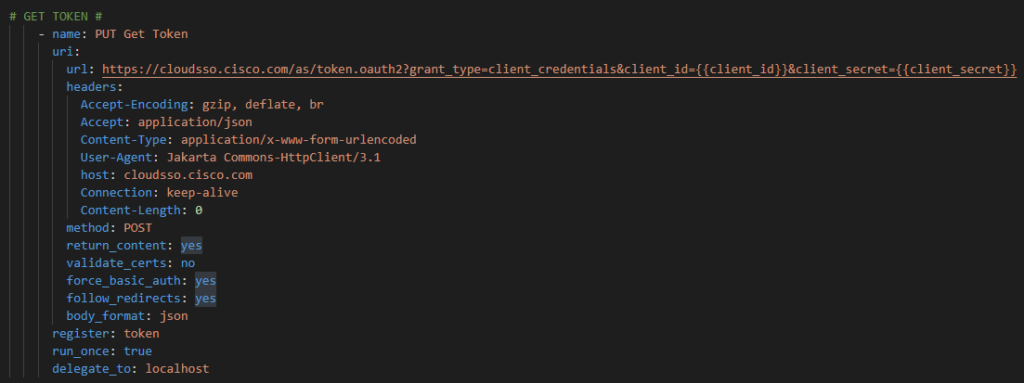
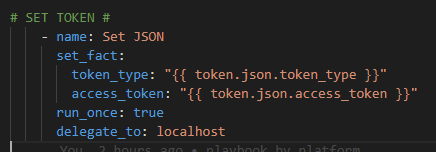
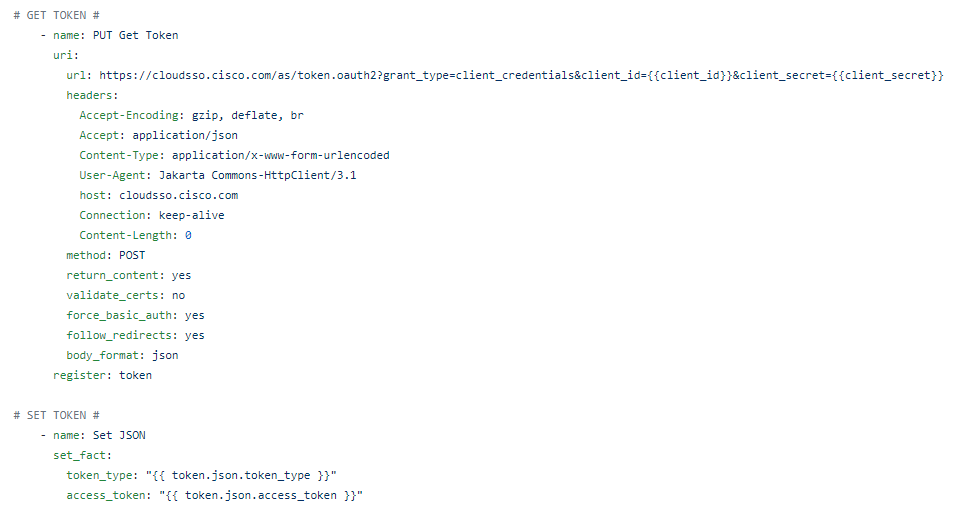
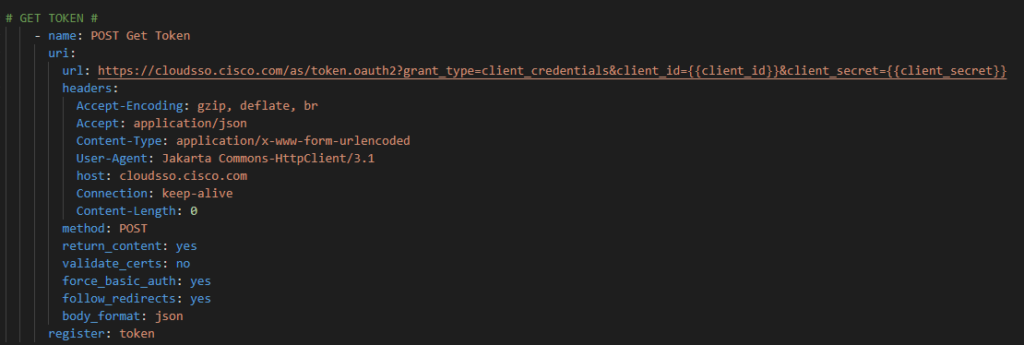
For now we will hard code our token – again once I figure this out I will just have another previous Ansible URI step to go get my token with prompted ClientID / Client Secret at the start of the playbook along with the Cisco credentials. Again, temporary work around

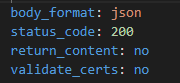
Again because I have used body_format: json I can write the body in YAML.
Let’s mix up the voice a little bit too so hit the Voices Reference Guide
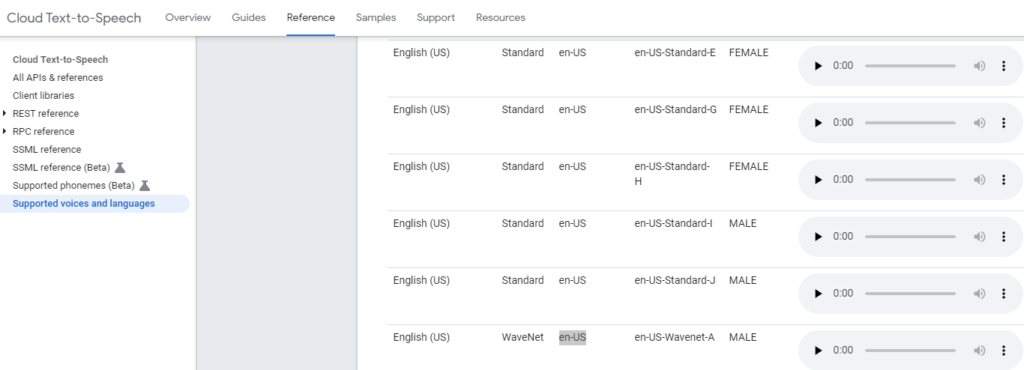
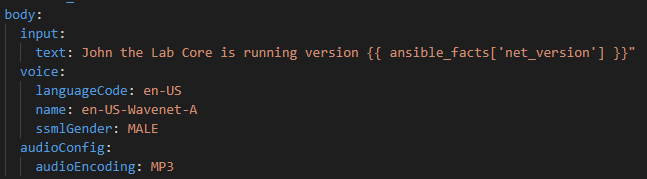
Ok so for our body let’s have some fun and try an English (US) WaveNet-A Male.
For the actual text lets mix a static string “John the Lab Core is running version” and then the magic Ansible Facts variable {{ ansible_facts[‘net_version’] }}
And see if this works
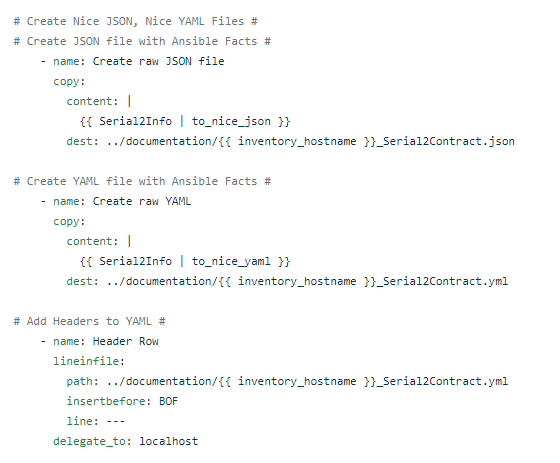
We need to register the response from the Google Cloud API and delegate the task to the localhost:

So now we need to parse and get just the base64-audio string into a text file. Just like in Postman this is contained in the json.audioContent key:

Now we have to decode the file! But this time with a Linux utility not a Windows utility
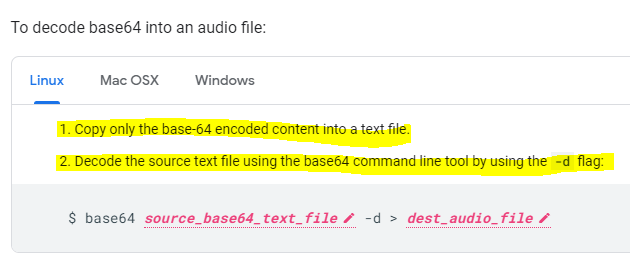
We can call the shell from Ansible easily to do this task:

Now in theory this should all work and I should get a text file and an MP3 file. Let’s run the playbook!
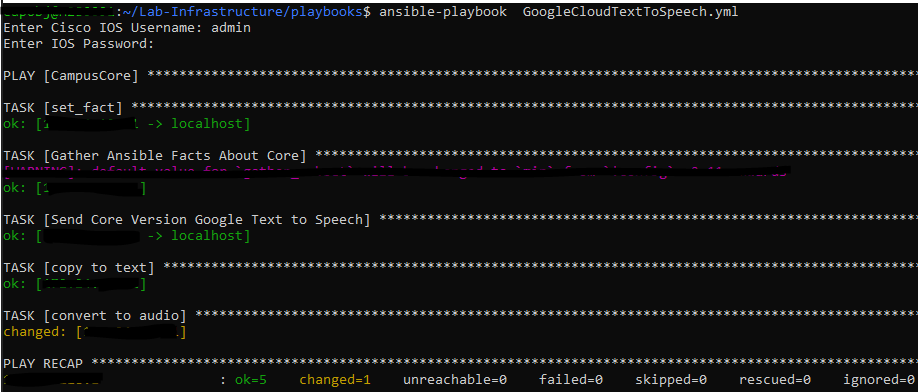
Lets check if Git picked a new file!

Ok ! What does it sound like!?!
Ok this is incredible!
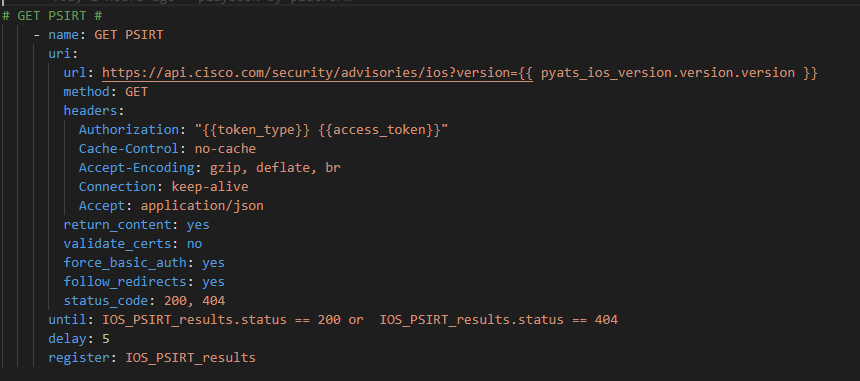
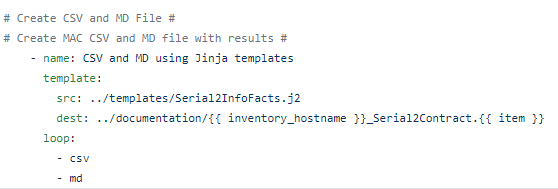
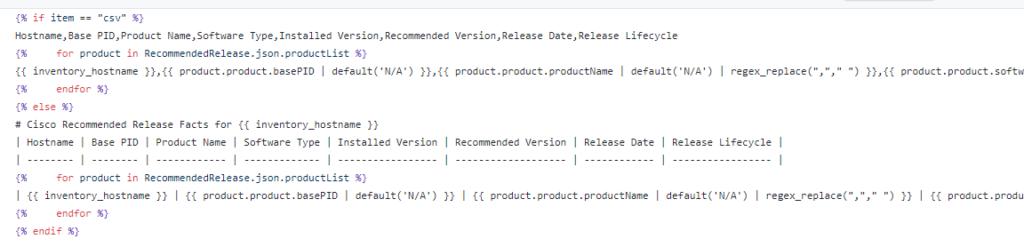
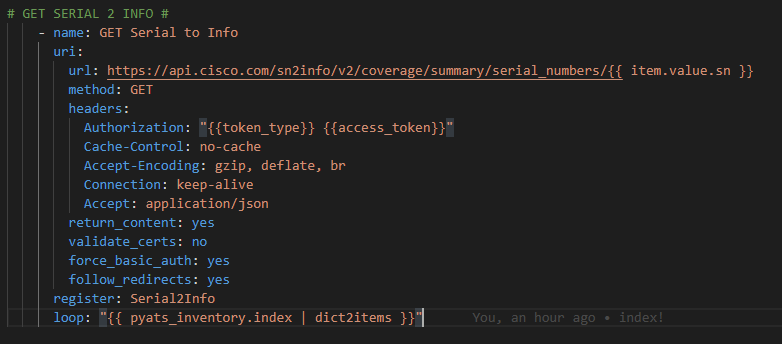
Let’s try some Genie / pyATS parsing and some different languages !
Copy and paste and rename the previous playbook and call the new file GoogleCloudTextToSpeech_Sh_Int_Status.yml
Replace the ios_facts task with the following tasks
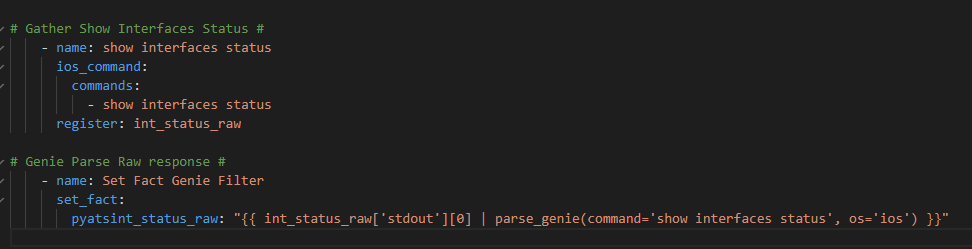
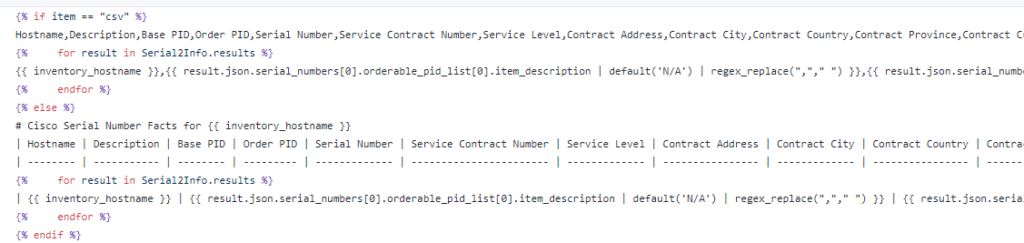
So now for our actual API call we want to conditionally loop over each interface if is DOWN / DOWN (meaning not UP / UP and not administratively DOWN)


Now as an experiment – let’s use French – Canadian in a Female Wavenet voice.
Does this also translate the English text to French? Do do I need to write the text en francais? Lets try it!
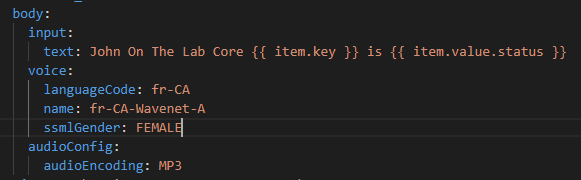
So this whole task now looks like this:
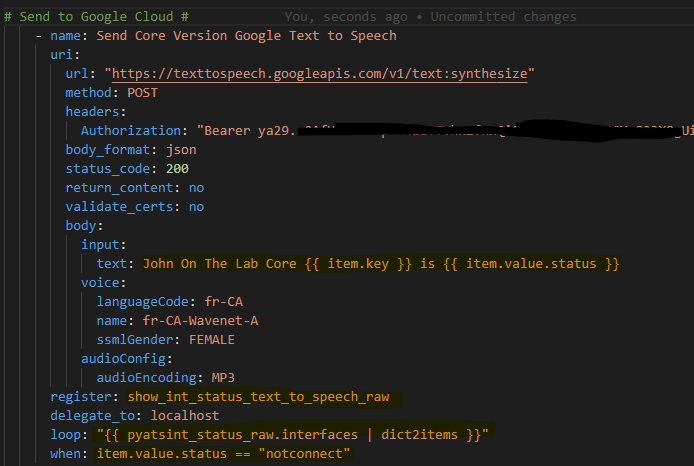
Now we need another loop and another condition to register the text from the results. We loop over the results of the first loop and when there is audioContent send that content to the text file.
Caution! RegEx ahead! Don’t be alarmed! Because of the “slashes” in an interface (Gigabit10/0/5) the file path will get messed up so let’s regex them to underscores

Then we need to decode the text files!

So let’s run the playbook!
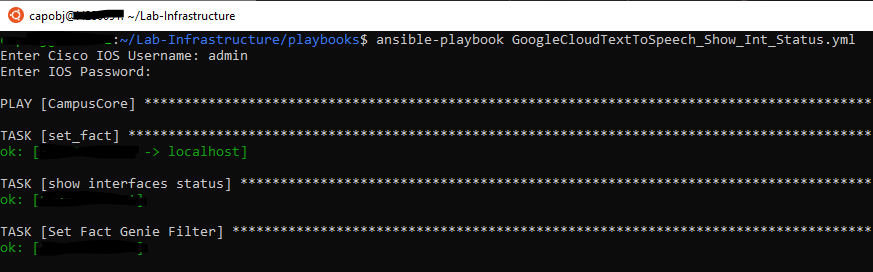
So far so good – now our conditionals should kick in – we should see some items skipped in light blue text then our match hits in green

Similarly, our next step should also have skipped items and then yellow text indicating the audioContent has been captured
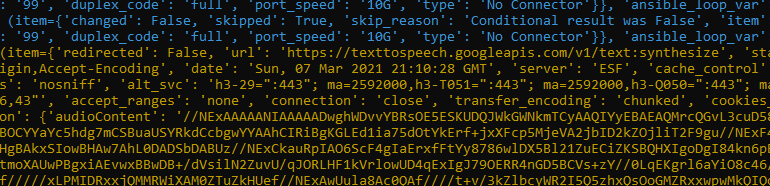
Which is finally converted to audio


What does it sound like!??! Did it automatically translate the text as well as convert it to speech?
TenGig
Gig
A little more fun with languages
I won’t post all the code but I’ve had a lot of fun with this !
How about the total number of port-channels on the Core – in Japanese ?!
Summary
In my opinion this Google Cloud API and network automation integration could change everything! Imagine if you will:
- Global, multilingual teams
- Elimination of technical text -> Human constructed phrasing, context, and simplicity
- Audio files in your source of truth
- Integrated with #chatops and #chatbots
- Visually impaired or otherwise physical challenges with text-based operations
- A talking network!
This was a lot of fun and I hope you found it interesting! I would love to hear your feedback!