For a while now, two NetClaw instances on opposite sides of the internet have been able to find each other. They peer over BGP through ngrok tunnels — real eBGP sessions, real identity routes, a real mesh directory — and each one shows up as a glowing node in the other’s 3D HUD. It’s a genuinely fun demo: two AI network engineers, each running someone else’s lab, exchanging /32s across the planet like it’s nothing.
But that mesh only ever answered one question: who is out there. It could not answer the far more interesting one: what can they do, and can I use it?
Today it can. We’re shipping N2N Federation — NetClaw-to-NetClaw — and with it a new protocol, NCFED, that turns the mesh from a map of who’s online into a working federation of AI engineers that can discover each other’s skills, invoke each other’s tools, and talk to each other’s agents. Safely. With consent on both sides, default-deny authorization, budgets, a kill switch, and an audit trail on every hop.
This is the post about how it works, why it needed a new protocol, and why we think it’s a bigger deal than it looks.
The itch
Picture three operators. John has a Cisco Modeling Labs server and a pyATS testbed. Nicholas has CML too, but also a Meraki org and a stack of automation John’s never written. Byrn has a Batfish setup and a Forward Networks digital twin John would kill for.
They’re already mesh-peered. John’s claw can see Nicholas’s claw and Byrn’s claw in the HUD. So why can’t John just ask his own NetClaw, “hey, does Nicholas have CML? Can you list his labs? And while you’re at it, ask Byrn’s claw why its OSPF area 0 keeps flapping”?
Nothing about that is science fiction. Each claw is already an agent with tools. Each pair already has an authenticated channel. The only thing missing was a protocol to carry capability inventories, tool calls, and conversations between them — and a trust model so nobody accidentally hands a stranger the keys to their lab.
Why a new protocol?
The first instinct is to reach for something off the shelf. There are two obvious candidates, and we looked hard at both.
MCP (Model Context Protocol) is what NetClaw already speaks internally — 111 integrations, all MCP servers, all tools/list and tools/call. It’s perfect for “run this tool and give me the result.” But it’s request/response by nature. It has no vocabulary for a long-running delegated task, no streaming, no notion of “an agent asking another agent to think about something.”
A2A (Agent2Agent) is purpose-built for exactly that: agent cards for capability discovery, a task lifecycle (submitted → working → completed), streaming messages. It’s a great semantic fit. But its transport binding assumes HTTPS and a well-known discovery URL per agent — which would mean every NetClaw exposing a new public endpoint, on top of the ngrok tunnel it already has. That breaks one of our hard rules (no new inbound exposure) and doubles the endpoint churn every operator already fights with free-tier ngrok.
So neither was a drop-in. But here’s the thing that made the decision easy: both A2A and MCP are JSON-RPC 2.0 under the hood. The disagreement between them isn’t the wire format — it’s the semantics and the transport binding. And we already own a transport: the authenticated mesh channel.
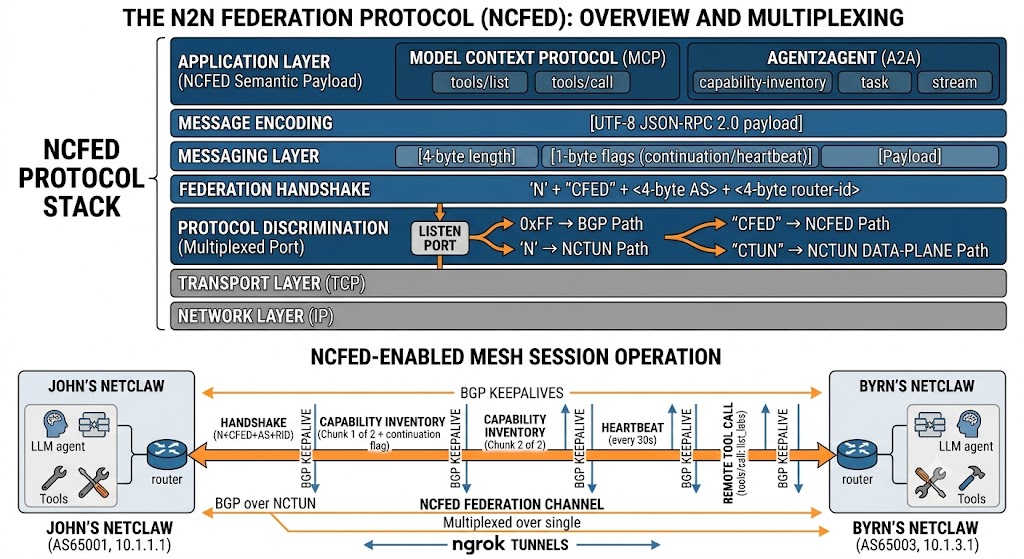
That’s NCFED. We took the semantics we wanted from each — MCP’s tools/call shape for deterministic tool invocation, A2A’s agent-card/task/stream shape for discovery, skill delegation, and chat — and bound them to a channel multiplexed over the mesh port we’re already using for BGP. Federation now works everywhere BGP works, with zero new open ports.
How NCFED rides the mesh
The NetClaw mesh daemon already does protocol discrimination on its listen port. When a TCP connection comes in, it peeks the first byte: 0xFF is a BGP marker, N is the start of our tunnel magic NCTUN. We added a third path. After the N, we read four more bytes: CTUN is the existing data-plane tunnel; CFED is a federation channel.
'N' + "CFED" + <4-byte AS> + <4-byte router-id> ← the NCFED handshake
That’s the whole trick. No new port, no new listener, no new ngrok tunnel. A federation channel is just another kind of connection to the same endpoint BGP already dials, disambiguated by five bytes. A NetClaw running the old code never sends NCFED, so it peers over BGP exactly as before and simply shows up as “not federated.” Backwards compatibility falls out for free.
Once the channel is up, it’s framed JSON-RPC 2.0:
[4-byte length][1-byte flags][UTF-8 JSON-RPC 2.0 payload]
The one flag that matters is continuation — a capability inventory with two hundred skills doesn’t fit in one frame, so large messages chunk, and BGP keepalives interleave between chunks. A heartbeat frame every 30 seconds keeps the channel honest. Identity is the BGP identity — as65001-4.4.4.4 — which means federation survives the thing that breaks everything else in this world: ngrok handing you a different endpoint after a restart. Your identity is your AS and router-id, not your address.

The four things it unlocks
1. Capability discovery. Once two operators mutually consent, each claw advertises a signed inventory: its skills (name + description), its MCP servers and their tool names, and coarse capability badges derived from what’s installed — CML, pyATS, Meraki, Batfish, Forward. Now John can ask his own claw “what can Nicholas do that I can’t?” and get an answer instantly from cached inventory, with a freshness timestamp. The inventory is built with a hard guard: it is scanned against every value in .env before it leaves the machine, and advertisement aborts if a secret would leak. Names and descriptions travel. Credentials, device addresses, and testbed contents never do.
2. Remote invocation. “List the labs on Nicholas’s CML.” John’s claw sends a tools/call over the channel. Nicholas’s claw checks its allowlist — default-deny, so nothing runs unless Nicholas explicitly granted John that specific tool. If the grant requires approval, Nicholas gets a prompt on whatever channel he’s using (Slack, Webex, CLI) and the request waits, expiring if he doesn’t answer. If it’s allowed, Nicholas’s claw runs the tool locally, with his own credentials and his own security policies, and returns only the result. Deterministic tools execute via a direct MCP stdio call — no LLM, no token cost. Skills delegate to Nicholas’s gateway agent, which reasons under his model, his DefenseClaw guardrails, and his budget. Every attempt — allowed, denied, approved, expired, timed out — lands in an audit record on both sides.
3. Claw-to-claw chat. “Ask Byrn’s claw why its OSPF area 0 is flapping.” The question relays to Byrn’s agent, which answers with its own tools and its own knowledge, and the reply streams back attributed to Byrn’s claw — John always knows he’s reading Byrn’s answer, not his own claw’s. Per-peer enable, rate-limited, budgeted, transcribed for both operators.
4. The HUD, alive. Every remote claw node in the 3D dashboard is now expandable. Click Nicholas’s node and it unfolds: his skills, his MCP tools, his capability badges, how fresh the inventory is, and a chat box wired straight to his agent. A federated claw glows differently from a merely-peered one. Federation state updates live as consent, inventory, and severance flow through.
The trust model, because this is the scary part
Letting another operator’s AI invoke tools on your machine is exactly as alarming as it sounds, so the guardrails are not optional and not bolted on:
- Mutual consent per peer. Nothing — not even a capability list — crosses until both operators opt in. Confirm your peer’s AS and router-id out of band first; you already coordinate ngrok endpoints in Slack, so you’re already doing this.
- Default-deny invocation. No grant, no execution. Grants are per-peer and per-tool, with an optional human-approval gate for anything sensitive.
- Budgets and rate limits. A peer using your claw draws against a per-peer daily budget of requests and tokens, on top of a per-minute rate limit. Nobody runs up your bill.
- No secrets, ever. Inventories and results carry capability names and outputs — never .env contents, credentials, or testbed data. Enforced at build time and tested as an invariant.
- Remote results are untrusted input. A result that says “now run rm -rf” is data, not a command. Your claw reasons over it; it never executes it.
- A real kill switch. Sever a peer and N2N stops in under ten seconds — capability exchange, invocation, chat, all of it — while the BGP session stays up and routes keep flowing. Federation and connectivity are decoupled on purpose.
- Dual-side audit. Both claws record who asked, what ran, when, and what came back.
Where this goes
Here’s why we think this is bigger than a neat trick. Every NetClaw is a specialist shaped by whoever runs it — their vendors, their labs, their hard-won skills. Federation makes that specialization composable without anyone surrendering control of their infrastructure. A CML expert’s claw can drive labs for a team that has none. A shop with a Forward Networks twin can answer path-analysis questions for peers who don’t. An on-call engineer at 3 a.m. can ask a peer’s claw — the one that actually knows that network — instead of paging a human. And it’s all mediated by agents that speak the same protocol, enforce the same consent, and write the same audit trail.
We built this the way we build everything in NetClaw: spec first, then plan, clarify, tasks, and implementation, with the whole thing tested on a two-daemon loopback before it ever touched the live mesh.
The mesh used to tell you who was out there. Now it tells you what they can do — and lets you, carefully and on both operators’ terms, actually use it.
NetClaws, assemble.
Written by John and Claude. NCFED, the N2N federation layer, and the HUD federation view were designed and implemented collaboratively — spec through deploy — as feature 052.
Part 2: Making the mesh hold — it actually works now (feature 053)
The post above ends with a working demo. Then we reached for something bigger — have one operator’s claw rebuild another operator’s entire CML lab over N2N — and the whole thing fell apart. Not because the protocol was wrong, but because the operational envelope was paper-thin. Nearly every session broke on one of: a long remote operation dropping mid-flight, a dead channel after a peer restart, an ngrok endpoint that moved on restart, a version difference between claws, or a timeout mismatch swallowing a completed answer.
That’s the tell: the protocol was sound; the resilience wasn’t there yet. Getting a working answer meant a human babysitting every restart. So we wrote spec 053 — reliability and ergonomics only, with the proven NCFED core frozen — and built six things.
1. Async task delegation — the headline. Long remote operations are no longer one blocking call. You submit a task and get a task_id in seconds; the peer runs it in the background; you poll short status calls and fetch the result when it’s done. No single call is ever long enough for ngrok to kill it.
> "Have Nick's claw recreate my NetClaw-Full-Topo lab in his CML."
n2n_delegate(peer="as65007-7.7.7.7", target_name="cml-lab-lifecycle", input="<10-node build spec>")
=> { task_id, state: "submitted" } # returns in ~2 seconds
n2n_task_status(task_id) => working - "nodes 4/10"
n2n_task_status(task_id) => working - "links 12/12, pushing configs"
n2n_task_result(task_id) => completed - "lab up, OSPF adjacency formed"
Task state is persisted, so the result survives a channel drop and a daemon restart mid-build.
2. Channel auto-reconnect. A background supervisor watches every federated peer. When a channel dies, it’s detected, the zombie is deregistered, and it re-establishes automatically from persisted consent with bounded backoff. A peer restart heals itself in under a minute, no human action.
3. Endpoint auto-re-announce. When your ngrok endpoint moves on restart, your claw announces the new one to federated peers over the still-live session and they re-dial automatically — validated only over the authenticated session, so it can’t be spoofed. The manual host:port dance in Slack is gone.
4. Capability negotiation. Peers exchange a small capability descriptor in the hello handshake — protocol version, which agent CLI flag they support, which reply shapes they emit — and each side adapts. A claw on an older build degrades gracefully instead of breaking. The –session-key vs –session-id skew that broke a whole afternoon is now just a negotiated field.
5. Robustness hardening. The live hot-patches became first-class, regression-tested requirements: the client always outlasts the server’s own timeouts; reply parsing tolerates a trailing log line after the JSON; the HTTP layer reads the full body even across TCP segments; missing fields return typed errors.
6. Health and one-step setup. n2n_health (and the 3D HUD claw node) show per-peer channel state, last-seen, endpoint freshness, and in-flight tasks with live progress. The old five-step setup collapsed into n2n_connect (add + consent + dial) and n2n_trust (consent + grants + chat).
It actually works — CML and Nautobot across the internet
On the live three-claw mesh — John (AS 65001), Nick (AS 65007), Byrn (AS 65099) — over nothing but N2N federation:
John’s claw asked Nick’s claw about its CML, and got the real answer:
Nick's CML labs - count: 1
Lab State Nodes
NetClaw OSPF 2R - 20260702-033650Z started 2
That traveled the full path: John’s claw to the NCFED channel to Nick’s claw running its own CML query with Nick’s own credentials, and back. No shared credentials, no John touching Nick’s CML — pure federation. Nick runs a different model (gpt-5.5) on a different OpenClaw build, and negotiation made the reply come back clean anyway. Byrn’s claw answered a Nautobot query the same way, peer-side under his own policies.
Then we tested the thing that matters most: it survives a reboot. After a full restart, John’s claw came back on the hardened code and both peers re-federated cleanly — Nick at his new address, Byrn at his — channels up, inventories fresh, via a single one-step connect. And as this was being written, John’s claw was teaching Nick’s claw the pyATS testbed for the CML lab they’d just cloned across N2N — one AI network engineer onboarding another, over a protocol that now holds.
What made it trustworthy: tests that fail first
Forty-four automated tests cover the federation layer, most driving two services over an in-memory channel pair, asserting the guarantees — submit returns fast while the op runs long, a result survives a channel drop and a daemon restart, a dead channel self-deregisters, a completed answer is never lost to a timeout mismatch, a pre-053 peer still federates. One of them immediately caught a missing import in the reconnect supervisor that would have silently prevented every auto-reconnect in production. The whole point of hardening is catching the thing that fails quietly.
A community of federated AI network engineers is only as good as its worst 3 a.m. failure mode. Spec 053 is the unglamorous work that turns a great demo into something you’d actually leave running. Three claws, three machines, three different models — discovering, querying, and delegating to each other across the internet, and healing themselves when one blinks. The mesh holds.
Next: an internal-clutch model (iN2N) for focused single-operator claw fleets. But first — the CML lab clone that started all this now completes, cleanly, over the mesh. Feature 053, built spec-through-implement over a live three-claw mesh, with a sharp –session-id catch from Nick and a client-payload PR from Byrn.